对于largebin attach的学习,这段时间决定好好复习一下基础。PWN还是很吃基础的。heap还有一些攻击方法,后续也会接着学习。
largebin attack
2.29的largebin attack可以说是unsortedbin attack的替代品。在2.29之前,unsortedbin attack的作用是能够在任意地址写入一个main_arena地址(可控的堆地址)。可以用来控制循环,或者伪造vtable打fsop。后者是在只能控制unsortedbin时一种很常用的一种攻击手法。然而由于2.29的保护措施,unsortedbin attack几乎不能使用了。
largebin attack原理
攻击产生的原因是在malloc时,如果在unsortedbin中没有找到可以切割的块,就会把他们按照各自的大小,放到smallbin和largebin中。在其中缺少对largebin跳表指针的检测。以下是入bin操作的源码。
1 | else |
注意看注释写的here2部分。这里能够像unsortedbin一样,往可控块写入当前堆地址。
1 | fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; |
在 largebin中 小于链表中最小的 chunk 的时候会执行前一句,反之执行后一句。当两者大小相同时,无法利用。
另外需要注意,伪造的堆块fd_nextsize需要设置为0.不然无法通过以下unlink检查。
1 | size = chunksize (victim); |
how2heap-largebin attack
现在的how2heap竟然有网页版了,方便很多
glibc2.27
首先程序分配了一个0x420的堆块,和一个0x20的保护堆块
1 | unsigned long *p1 = malloc(0x420); // chunk1 |
接下来分配了一个新的0x500的堆块。和一个保护堆块,之后再次重复。
1 | unsigned long *p2 = malloc(0x500); // chunk2 |
之后free(p1),free(p2),他们会被放在unsortedbin中。
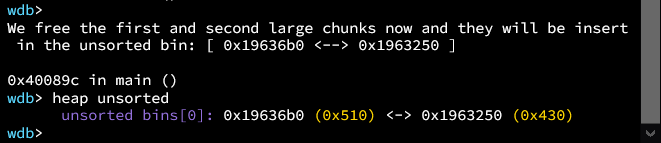
接下来**malloc(0x90)**这将会从unsortedbin末尾chunk中切割出0xa0大小空间,并把0x510的chunk放到largebin中,然后剩下的0x430-0xa0的chunk,仍然被放回到unsortedbin中。这一步完成了许多过程
- 从 unsorted bin 中拿出最后一个 chunk(p1 属于 small bin 的范围)
- 把这个 chunk 放入 small bin 中,并标记这个 small bin 有空闲的 chunk
- 再从 unsorted bin 中拿出最后一个 chunk(p2 属于 large bin 的范围)
- 把这个 chunk 放入 large bin 中,并标记这个 large bin 有空闲的 chunk
- 现在 unsorted bin 为空,从 small bin (p1)中分配一个小的 chunk 满足请求 0x90,并把剩下的 chunk(0x330 - 0xa0)放入 unsorted bin 中
如下图。
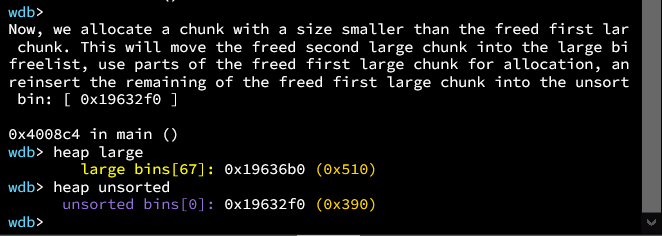
接下来释放chunk3。他会被插入到unsortedbin中。可以看到是插在最前面。
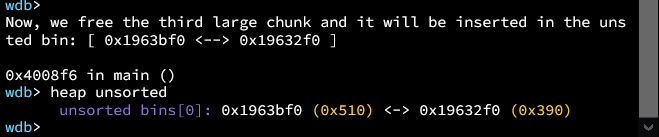
接下来是触发部分。设置p2(在largebins中的块)先看一下没改的时候堆布局
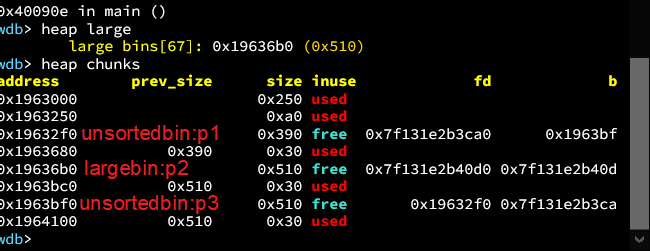
将largebin按照如下方式修改。改自身size,bk和bk_nextsize。fd和fd_nextsize均写为0,按照前面所说的。

在接下来分配0x90的块,使得unsortedbin中的chunk能够插入largebin之前,先看一下堆布局。
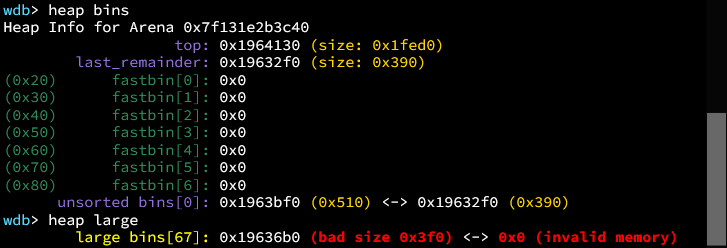
之后,就能成功写入两个值。写入的是被插入unsortedbin中的chunk地址。
这是因为当前插入的chunk属于largebin,大小为0x410(取出Unsortedbin,放入对应largebin中)寻找到fwd的size是0x3f0被我们修改过,小于0x410,会相应的执行这一句
1 | victim->bk_nextsize = fwd->bk_nextsize |
注意这里的fwd是经过遍历比较找到的正好比自己小的那个chunk。这里0x3f0正好比自己小。插入在0x3f0后面。此时执行上述代码,相当于利用原先largebin中我们伪造好的指针,写入了main arena数据此时应该修改了var2,因为它在bk_nextsize位置。
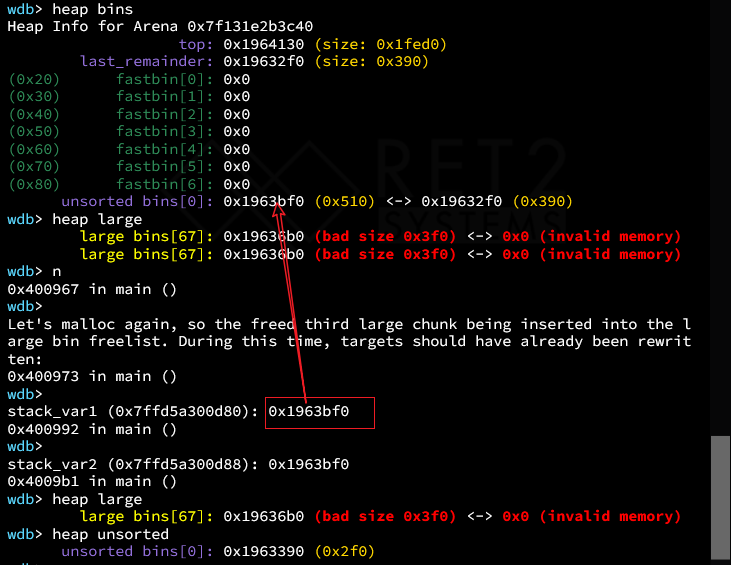
同时,可以看到var1也被修改了,因为存在以下利用。
1 | bck->fd = victim; |
相当于是这个chunk入链的操作,这里和nusortedbin attack一模一样。
总结-2.27
利用largebin attack的条件,和能够达成的效果。
条件:
可以修改一个 large bin chunk 的 data
- victim chunk’s size修改成比下一个进来的chunk小即可,但是要确保被修改的首先被存放在largebins中,因为要从 unsorted bin 中来的 large bin chunk 要紧跟在被构造过的 chunk 的后面
- fd_nextsize修改为0
- 修改fd_nextsize为target-0x20,fd为target-0x10,就可以在这两个地方写入数据
效果:
通过 large bin attack 可以辅助 Tcache Stash Unlink+ 攻击
可以修改 _IO_list_all 便于伪造 _IO_FILE 结构体进行 FSOP
注意:
unsortedbin插入在头部,取出在尾部
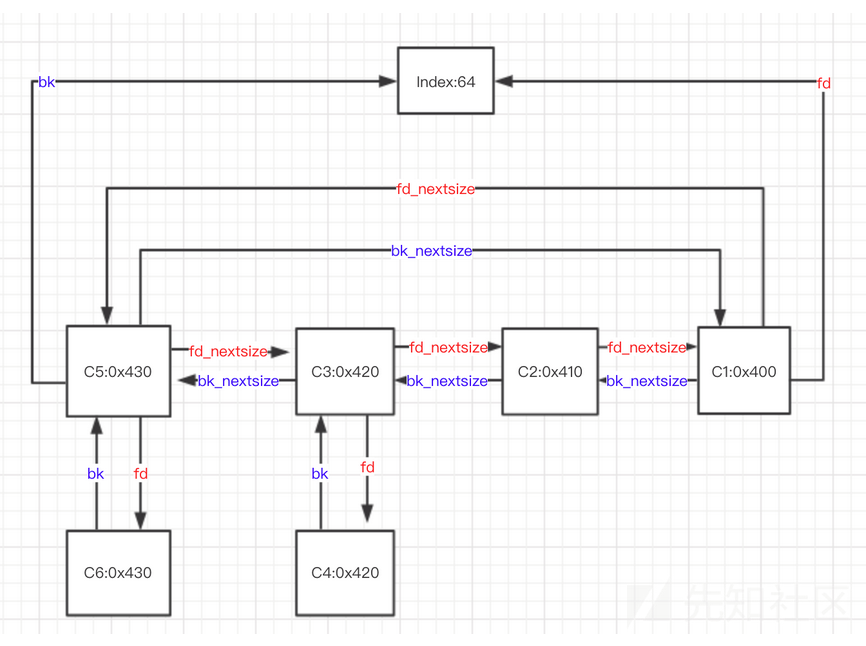
largebin中
- 按照大小从大到小排序
- 若大小相同,按照free时间排序
- 若干个大小相同的堆块,只有首堆块的
fd_nextsize和bk_nextsize会指向其他堆块,后面的堆块的fd_nextsize和bk_nextsize均为0- size最大的chunk的
bk_nextsize指向最小的chunk; size最小的chunk的fd_nextsize指向最大的chunk
glibc2.31
glibc2.31为largebin添加了两条类似unsortedbin中的检查。分别检查bck和bk指针是否被修改过。
1 | if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk)){ |
绕过此检查的基本思路是:分配一个最小的chunk到largebin中,如果当前块比这个bin中所有块都要小,就能够绕过检验,直接写入。注意上面是改的较小的chunk,这里是较大的。然后最小的chunk
接下来是how2heap的做法
首先是创建了0x428,0x18,0x418,0x18四个chunk。记0x428的chunk为p1,0x418的chunk为p2。大小选择需要确保p2小于p1,并且两个在同一个bins中。
接着释放p1(较大的那个),p1将存在于unsortedbin中,分配一个p3(比p1大)让p1进入largebin。现在bins如下所示。
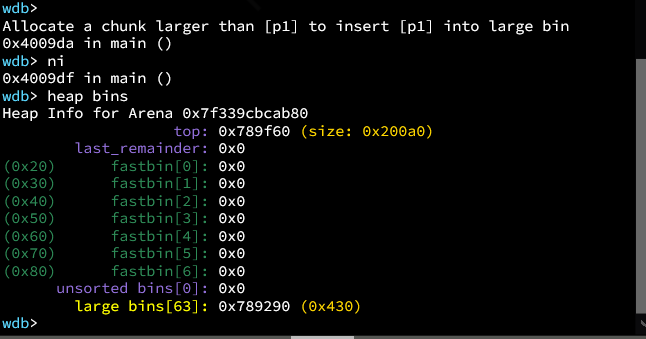
之后释放p2,p2进入unsortedbin。如下图
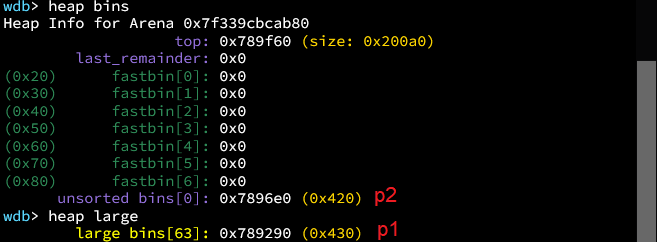
现在修改p1的bk_nextsize为我们想要的地址-0x20

之后创建一个chunk,使得unsortedbin中的chunk(p2)被放入largebin中。注意,此时p2大小是小于p1的。
此时glibc有一个机制:当被放入的chunk是当前largebin中最小的chunk时,不会检查
chunk->bk_nextsize。我们上述修改就会生效。
此时,目标地址将写入原先在unsortedbin中的chunk的地址。
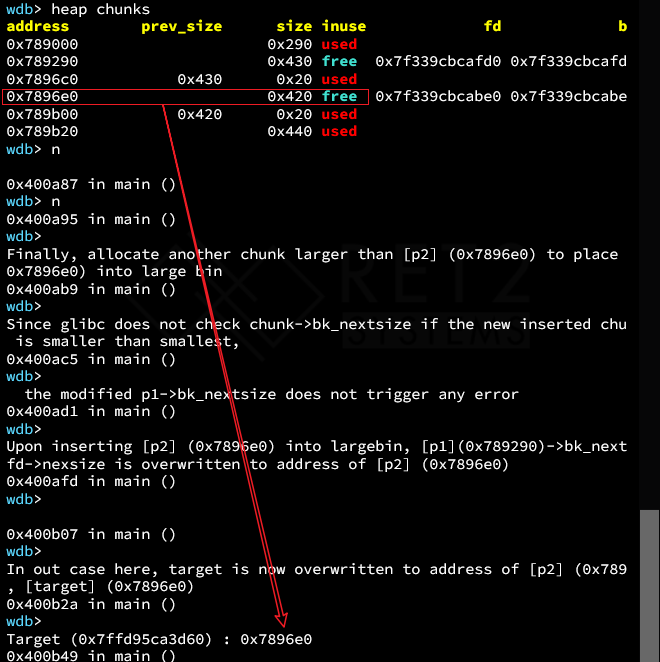
这里修改的又是较大的chunk,可能会感到疑惑?
这是因为largebin 的fd_nextsize和bk_nextsize构成的是一个环形链表。可能需要记住的是在2.31中,修改的是较大块,在2.27之前,修改的是较小的。
参考链接
https://www.anquanke.com/post/id/189848
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/large-bin-attack/