fuzz零基础第一课——fuzz关键思想、AFL实现综述
AFL实现阅读笔记
控制流侦测
大致了解了一下AFL的实现。AFL的本质还是动态插桩,其插桩的方式是在汇编语言角度上根据控制流形成的一种插桩手法。为此,afl专门使用了自己的编译器afl-gcc/afl-clang以及汇编器afl-as。在使用此编译器之后,插入程序的汇编代码如下。
1 | fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); |
1 | static const u8* trampoline_fmt_32 = |
除了保存一些寄存器之外,程序调用了__afl_maybe_log(将在下面说明)。(保存寄存器的地方注意ecx保存了sprintf的参数 R(MAP_SIZE))。这是一个随机数,用来标识程序当前执行到哪个控制块。
何时调用sprintf呢?网上有文章说是
在处理到某个分支,需要插入桩代码时,afl-as会生成一个随机数,作为运行时保存在ecx中的值。但是也没有说清楚什么是分支,以及怎么判断分支。
我觉得这是比较巧妙的。fuzz的实现这里可以理解为基于达到了多少控制流。看到这里也许脑海中已经对fuzz的基本思路有了一个想法。
fork-server
可想而知的是fuzzer一定会多次导致程序崩溃,那么必然要执行多次execve操作,这样将很花时间(这篇博客有提到)。一个解决办法是使用一个fork-server。因为所有的fork都是写时复制,比较节省调用开销。从而AFL的逻辑是:fuzzer生成一个fork-server,之后在fuzzer和fork-server之间通信。包括fuzzer告知fork-server可以开始fork,以及在fork-server fork子进程运行完毕之后告知fuzzer子进程运行状况。大致的思路是这样。
为什么要这么做?
我个人认为是想要便于处理。mit6.828里面文件系统部分也是IPC通信,和这个还是比较类似的,甚至更复杂一些。
消息传递?
怎样在fork-server和fuzzer之间传递信息呢?阅读源码发现主要是通过一个共享内存的方式传递的。
1 | shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600); |
分支信息的记录
具体一点讲,怎么记录fork出来的子进程覆盖了多少代码呢?
由官网文档可知,AFL是根据二元tuple(跳转的源地址和目标地址)来记录分支信息,从而获取target的执行流程和代码覆盖情况,其伪代码如下:
1 | cur_location = <COMPILE_TIME_RANDOM>; |
AFL通过写入之前提到的共享内存,作为记录执行了多少分支的依据。从上面的伪代码可以看出,cur_location就是一个随机数,是在控制流侦测中 R(MAP_SIZE)生成的。通过把cur_location和prev_location异或,就能够得到一个能够标志某个分支的key。
AFL为每个代码块生成一个随机数,作为其“位置”的记录;随后,对分支处的”源位置“和”目标位置“进行异或,并将异或的结果作为该分支的key,保存每个分支的执行次数
这里比较迷惑的是为什么要prev_location = cur_location >> 1;文档里面给出的解释是
官方文档中解释了这样做的原因。假设target中存在
A->A和B->B这样两个跳转,如果不右移,那么这两个分支对应的异或后的key都是0,从而无法区分;另一个例子是A->B和B->A,如果不右移,这两个分支对应的异或后的key也是相同的
一开始我还是有疑惑,那不就相当于修改了cur_location为另一个数值了吗,如果A->B->C是一个执行流,那么是不是有可能存在一个A->D->C的B->C和D->C部分碰撞呢?这里可能是hashmap碰撞检测的部分。因为只需要B和C不相同就可以了。(那么+1之后也不会相同)
需要注意到的是,作为目标地址的A和作为起始地址的A可以理解为带有不同的信息,因此**+1影响到地址改变只是一种错觉**。
看一下完整的源码,如下:
1 | "__afl_store:\n" |
分支信息的处理
在fuzzer接收到fork-server发出的共享内存信息之后(回想一下,共享内存是什么:是一个hashmap,记录了每个路径执行的次数。)fuzzer自然不能将这些信息全部存起来,需要进行一些处理并分析。目的之一肯定是压缩信息(不然每次共享内存无法得到回收,开销太大)以下就是fuzzer处理分支信息的方式。
借助于上面提到的某个分支的hash值,我们可以简单地用一个桶结构记录某个路径被执行了多少次。这样的好处是,对于一些比较细小差别的执行次数(例如A分支执行了10次,B执行了11次)就把他们归为一类。之后将所有的分支桶中的代码块标志hash一下,变成当前执行结果的输出。
1 | static const u8 count_class_lookup8[256] = { |
举个例子,如果某分支执行了1次,那么落入第2个bucket,其计数byte仍为1;如果某分支执行了4次,那么落入第5个bucket,其计数byte将变为8,等等。fuzzer对fork-server传回的共享内存作上述处理之后,将一次结果保存下来。之后继续进行下一次的fuzz。
通过把稀疏的map结构转变为桶结构,能够压缩一定的空间。
文件变异
AFL提供的主要的文件变异种类有以下几种
- bitflip,按位翻转,1变为0,0变为1
- arithmetic,整数加/减算术运算
- interest,把一些特殊内容替换到原文件中
- dictionary,把自动生成或用户提供的token替换/插入到原文件中
- havoc,中文意思是“大破坏”,此阶段会对原文件进行大量变异,具体见下文
- splice,中文意思是“绞接”,此阶段会将两个文件拼接起来得到一个新的文件
这些变异方法也不是随机变的,例如bitflip中,AFL可以通过每一字节、两字节、四字节、八字节的方法改变文件中的比特串,从而识别出哪些比特串是tag(也就是文件标识符,例如ELF文件开头的ELF),又比如进行一个byte级别的反转时,如果执行路径没有发生变化,那么说明这个byte很有可能属于data部分,而不是”metadata”。因此这样变化带来的意义就不大,从而后面多个byte的变异就可以跳过这些byte。
这里另外一个比较有意思的地方是havoc大破坏,它确实能造成很大的破坏。具体来说,havoc包含了对原文件的多轮变异,每一轮都是将多种方式组合(stacked)而成:
- 随机选取某个bit进行翻转
- 随机选取某个byte,将其设置为随机的interesting value
- 随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
- 随机选取某个byte,对其减去一个随机数
- 随机选取某个byte,对其加上一个随机数
- 随机选取某个word,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个word,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
- 随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
- 随机选取某个byte,将其设置为随机数
- 随机删除一段bytes
- 随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
- 随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
- 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
此外,interest这里还会给出一些常见的特殊data,如下
1 | /* List of interesting values to use in fuzzing. */ |
这些都是容易导致出现bug的字符。
还有一些别的,这篇文章讲的灰常清楚,我这里就不重复了。至此应该对AFL的基本实现有一定的了解。
afl-fuzz环境配置
不得不说环境配置真是搞人心态。我总共前前后后花了大概三天时间。一开始看fuzzing010讲的是用gcc的,但是无论如何耶不行,一直出现not instrumented标记,上网查也没找到解决方法。所以下定决心看一看AFL官网配置文件中的,不走捷径。
不看不知道,官网中说明白了,编译器的选择是llvm比gcc好。于是我后面选择的都是llvm。
安装llvm
1 | echo deb http://apt.llvm.org/NAME/ llvm-toolchain-NAME NAME >> /etc/apt/sources.list |
编译二进制文件时插桩
从上面的分析中可以看到AFL的原理其实就是在编译时插桩,从而记录各种各样的代码块执行情况。我们用以下命令控制编译文件的方式(使用afl-clang-lto以及afl-clang-lto++)。
1 | CC=afl-clang-lto CXX=afl-clang-lto++ RANLIB=llvm-ranlib AR=llvm-ar ./configure |
如果一切正常,终端**不会显示”C compiler cannot create executables”**。一旦显示说明当前编译器选择不正确。最好检查上面安装llvm过程是否出现了问题。
使用llvm进行fuzz
这里采用的是fuzzing010的命令。
1 | afl-fuzz -i $HOME/fuzzing_xpdf/pdf_examples/ -o $HOME/fuzzing_xpdf/out/ -s 123 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output |
这句话是什么意思呢?
- -i indicates the directory where we have to put the input cases (a.k.a file examples)
- -o indicates the directory where AFL++ will store the mutated files
- -s indicates the static random seed to use
- @@ is the placeholder target’s command line that AFL will substitute with each input file name
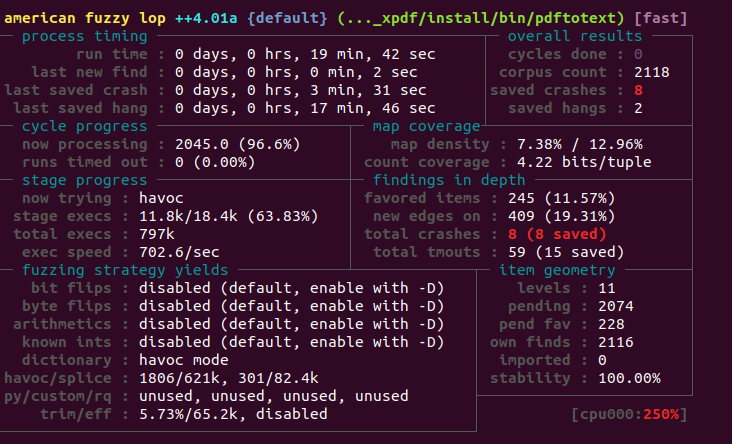
正常情况下,执行后会得到这样的输出。
分析crash
作为ics的学习经验,一开始尝试做lab出发点是好的,但是结果一般还是得看别人的解答。但是我头比较铁。
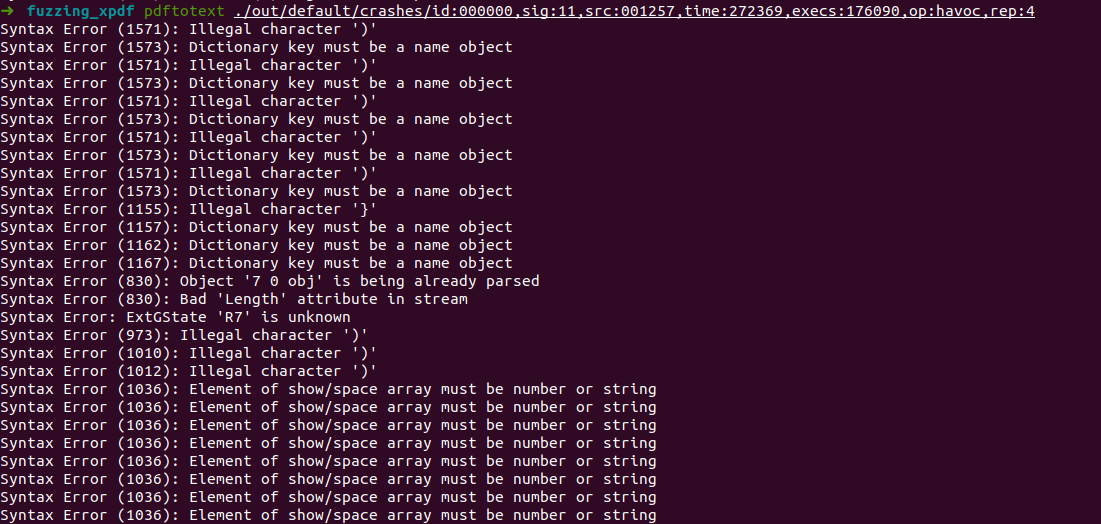
选择crash里面第一个来分析,输出这些内容,使用gdb尝试调试
想要用gdb传入参数,使用以下命令(注意到pdfinfo在install/bin文件夹下,这里先进入文件夹)
1 | gdb ./pdfinfo --args ../../out/default/crashes/id:000001,sig:11,src:001598,time:460946,execs:312004,op:havoc,rep:2.txt |
好像输出不太对?

投降,去看看答案怎么写(毕竟是第一次做,不知道怎么做很正常,蒽)
答案说的crash里面是有segmentation fault的,但是我的没有??(可能这个就是unique crash吗)。上网查了一下,发现输出的crash里面其实有信号类型。(可以看到下面sig:11的位置)
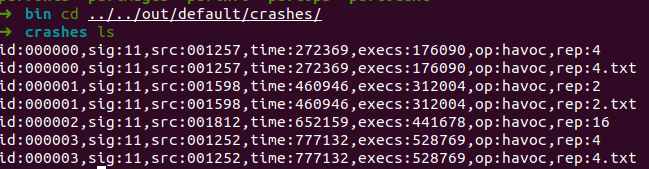
在wiki上面查到,11对应的错误就是segmentation fault?

查了一下unique_crash是什么。指的是和当前crash相关的程序执行流没有在之前的crash情况中碰到过。那会不会是我AFL配置的有问题?(回想起来我是用LLVM编译的)

经过各种尝试,终于分析到结果了。如下所示。之前没有下载一张helloworld.pdf的托i按,现在下载下来就有了(只能说样本对于fuzz关系很微妙啊)
调试样本
1 | gdb ~/fuzzing_xpdf/install/bin/pdftotext |
以上语句设置gdb的路径以及参数。这里我和答案做法不一样,答案还带符号编译了一下,但是我就用llvm编译的结果就是有符号的。
运行之后结果如下

使用backtrace或者bt可以看到以下内容
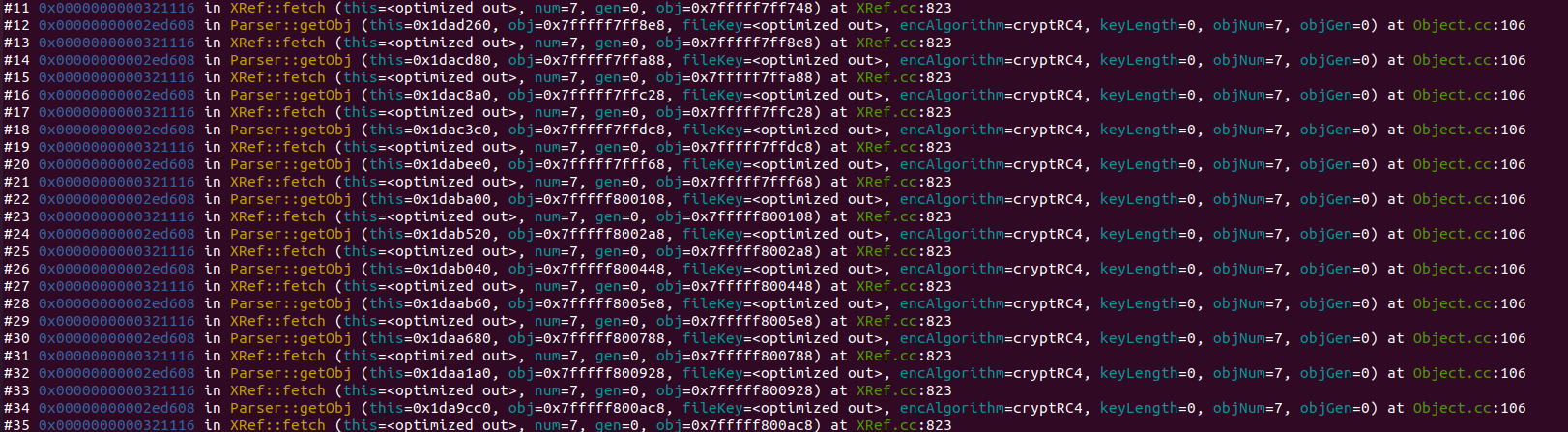
可以看到程序递归调用了parser::getObj这里的函数,导致出现了爆栈。
1 | 11 0x0000000000321116 in XRef::fetch (this=<optimized out>, num=7, gen=0, obj=0x7fffff7ff748) at XRef.cc:823 |
调试源码
找到了问题所在,可以回头看一下源码。发现确实存在递归调用
1 | // XRef.cc |
1 | // Object.cc |
可以看到上面这两个方法循环的调用了自己。到此完成了这次lab的学习。