有关使用LCOV完成对code coverage的覆盖检测。
相关文件:LibTIFF
code_coverage
在fuzzingbook上面学习有关code_coverage的理论知识。
black/white box
黑盒测试的好处在于,能够将一个指定的内容进行测试。我们可以设置输入的内容,可以让我们在部署好测试方案之前开始测试。但是与之带来的缺点就是代码覆盖面相对较窄。白盒测试正好相反,白盒测试缺点可能是我们部署的方案不一定有效,但是优点就在于可以覆盖更广的代码。
那么我们怎么衡量fuzzer覆盖的全面与否呢?就是通过计算code coverage。
python中的追踪
大部分的程序设计语言很难做到对于每一步的运行过程进行追踪,python可以做到。利用以下函数即可。
1 | sys.settrace(f) |
例如,一个trace回调函数如下.这个回调函数的作用是记录每一次调用的python代码的行号。
1 | def traceit(frame: FrameType, event: str, arg: Any) -> Optional[Callable]: |
编写一个包装函数,用来调用sys.settrace和释放sys.settrace
1 | def cgi_decode_traced(s: str) -> None: |
接下来就可以调用这个包装函数了
1 | cgi_decode_traced("a+b") |
如果我们打印coverage的集合形式(去除重复的行号之后的结果),如下
1 | covered_lines = set(coverage) |
如果想用可视化形式表示,并且打印出执行了什么代码,可以按照如下方法。考虑先打印一个”#”,并且不换行(如果行号不在执行过的语句中),之后打印代码行。
1 | # 获取一个函数的源码 |
结果如下。注意这是合理的,因为我们的输入是a+b,之然不会到百分号所在的分支中。
1 | # 1 def cgi_decode(s: str) -> str: |
我们同样可以写脚本判断哪一次执行将带入新的行数,以及能够运行多少行。
coverage类
之前我们显式的调用了traceit(),现在我们尝试把他整合到一个类里面去,让类帮我们完成初始化和释放操作。使用如下的python方法
1 | with OBJECT [as VARIABLE]: |
在执行这条语句的时候,我们将会在OBJECT被实例化和储存VARIABLE的情况下在执行BODY。比较有趣的事情是在BODY的开始和结束,OBJECT.enter()以及OBJECT.exit()会被隐式调用。我们就可以在这两个初始化、结束函数中放入之前的trace初始化和释放函数。
1 | import inspect |
with Coverage() as cov:
function_to_be_traced()
c = cov.coverage()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
"""
# 初始化一个用于储存所有被执行的行数的list
# location是一个(function,line number)的list
def __init__(self) -> None:
"""Constructor"""
self._trace: List[Location] = []
# Trace function
def traceit(self, frame: FrameType, event: str, arg: Any) -> Optional[Callable]:
"""Tracing function. To be overloaded in subclasses."""
if self.original_trace_function is not None:
self.original_trace_function(frame, event, arg)
if event == "line":
function_name = frame.f_code.co_name
lineno = frame.f_lineno
if function_name != '__exit__': # avoid tracing ourselves:
self._trace.append((function_name, lineno))
return self.traceit
# 进入with之后将被执行
def __enter__(self) -> Any:
"""Start of `with` block. Turn on tracing."""
self.original_trace_function = sys.gettrace()
sys.settrace(self.traceit)
return self
# 退出时执行
def __exit__(self, exc_type: Type, exc_value: BaseException,
tb: TracebackType) -> Optional[bool]:
"""End of `with` block. Turn off tracing."""
sys.settrace(self.original_trace_function)
return None # default: pass all exceptions
# 返回trace的list
def trace(self) -> List[Location]:
"""The list of executed lines, as (function_name, line_number) pairs"""
return self._trace
def coverage(self) -> Set[Location]:
"""The set of executed lines, as (function_name, line_number) pairs"""
return set(self.trace())
def function_names(self) -> Set[str]:
"""The set of function names seen"""
return set(function_name for (function_name, line_number) in self.coverage())
# 打印出带有源码的执行与否标记,当直接调用print()时执行
def __repr__(self) -> str:
"""Return a string representation of this object.
Show covered (and uncovered) program code"""
t = ""
for function_name in self.function_names():
# Similar code as in the example above
try:
fun = eval(function_name)
except Exception as exc:
t += f"Skipping {function_name}: {exc}"
continue
source_lines, start_line_number = inspect.getsourcelines(fun)
for lineno in range(start_line_number, start_line_number + len(source_lines)):
if (function_name, lineno) in self.trace():
t += "# "
else:
t += " "
t += "%2d " % lineno
t += source_lines[lineno - start_line_number]
return t
之后就可以用以下代码来简单的trace某个函数。
1 | with Coverage() as cov: |
可以用来输出执行的行号
1 | with Coverage() as cov: |
如果直接print(cov)将相当于调用重载的repr输出带有某一句执行与否的源码。带”#”表示执行过。
1 | print(cov) |
我们还可以比较两个coverage,因为他们带有集合的性质。
1 | with Coverage() as cov_plus: |
c中的追踪
对于c程序,我们有编译器自带的代码覆盖检测工具gcov。首先介绍一下如何使用gcov。
对于小的程序(好叭,就是不用makefile的程序而言)使用gcc编译时加上以下参数
1 | -fprofile-arcs -ftest-coverage |
就能够生成二进制程序,测试执行的代码覆盖面积。
我们正常运行一个程序之后,使用如下代码测试代码覆盖率

在同文件夹路径下生成的gcov文件,可以用来分析每行代码执行次数。这里截取了main函数部分。
1 | 1: 46:int main(int argc, char *argv[]) { |
注意,最左侧代表执行次数。如果是大于0的数字代表执行次数,”-“代表这一行不能执行,”#####”代表这一行没有被执行到。使用以下python脚本,可以实现对生成的gcov文件进行分析。下面代码的作用是读取gcov文件,将执行过的行号记录在一个set中,并输出。最后我们就能够得到本文件有哪些行被执行。
1 | def read_gcov_coverage(c_file): |
使用以下命令
1 | coverage = read_gcov_coverage('cgi_decode.c') |
fuzz的优越性
其实上面的代码是有Bug的,作者留了一手没有说,就是为了fuzzer这里提到。就是当碰到百分号时,我们会往后取两个数字,因为要转义成相应的ascii字符。这里就可能出现越界读。例如考虑以下内容
1 | 82 202*&<1&($34\'"/\'.<5/!8"\'5:!4))%; |
这里就会尝试读取末尾百分号后面的分号,以及分号之后的(没有了!)这可能导致信息泄露,或者segmentation fault。如果程序位于c语言中,问题将会更加明显,(问题在下两行中)
1 | int digit_high = *++s; |
我们之前讨论了许多代码如何覆盖,也没有看出来这个问题。
基础知识的总结
了解coverage更重要的其实是对于fuzz提供一个衡量标准。
主要学到了
- coverage类以及相关使用方法(输出执行过的代码或者函数、输出代码执行次数、输出执行流程)
- c语言中编译器自带代码执行覆盖分析工具gcov。已经集成在gcc中。我们需要先运行程序,(将在相同路径下生成.gcda和.gcno),之后使用gcov对.c文件进行分析。
fuzz101环境
麻了,之前的source forge和github都不管用了,答案用的是osgeo,真的不知道是怎么找的。环境的链接不搬运了,都在网站的solution里面。
这次学习的重点是使用lcov以及asan工具。其中asan用来便于找到内存污点,lcov用于输出fuzzing的覆盖面。这次练习就是学会把这三个工具组合起来使用。
第一步还是编译,使用AFL++和ASAN编译。AFL_USE_ASAN=1就相当于指定了使用ASAN。
1 | export LLVM_CONFIG="llvm-config-11" |
依然是使用如下代码开始fuzzing
1 | afl-fuzz -m none -i $HOME/fuzzing_tiff/tiff-4.0.4/test/images/ -o $HOME/fuzzing_tiff/out/ -s 123 -- $HOME/fuzzing_tiff/install/bin/tiffinfo -D -j -c -r -s -w @@ |
找到了巨多的错
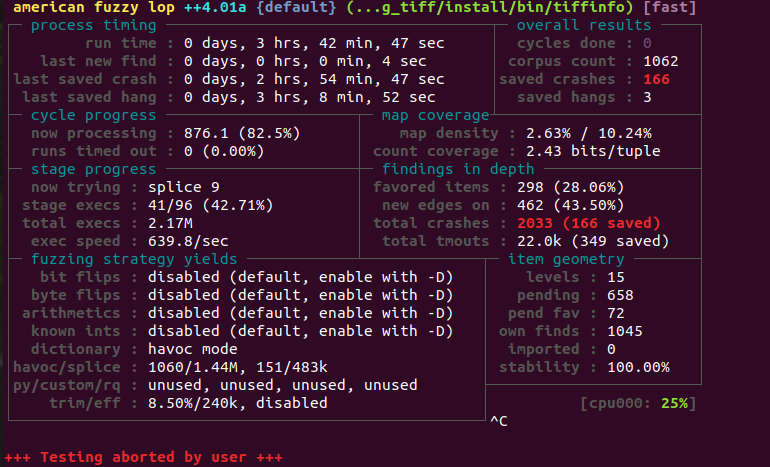
fuzzing结果
随便尝试了运行一个,ASAN很清楚地给出了我们错误所在(这个工具tql)
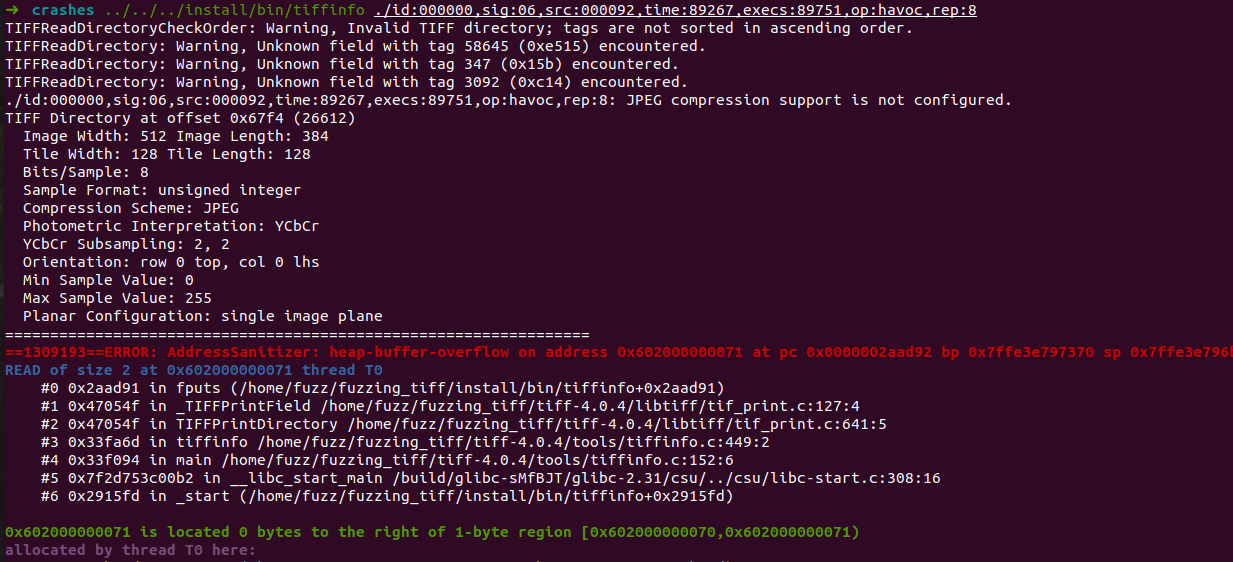
以下是ASAN输出的影子堆栈。不过这个输出是有特定含义的。
- 8 字节的数据可读写,则 shadow memory 的值为 0
- 8 字节的数据不可读写,则 shadow memory 的值为负数,如
0xfa表示堆左边的 redzone、0xf1表示栈左边的 redzone. ASan 也根据这个值在报错的时候输出对应的错误类型,如区分heap-buffer-underflow/stack-buffer-underflow - 前 k 个字节可读写,后 8 - k 个字节不可读写,则 shadow memory 的值为 k,k 的取值范围为
[1, 7]
借用下面这张图,可以看得更清楚,先举一个例子,参考的是这篇文章,写的非常好
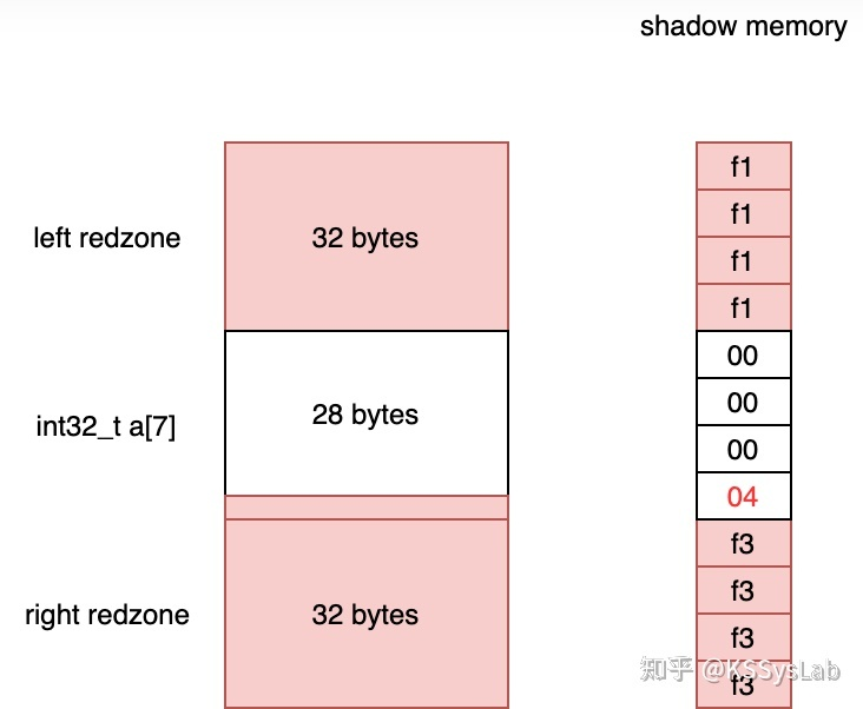
f1表示stack-left,f3表示stack right。同时,中间的28bytes末尾也被标记为04,表示只有四字节可以写。(05表示5字节可写,以此类推)
结合我们的输出
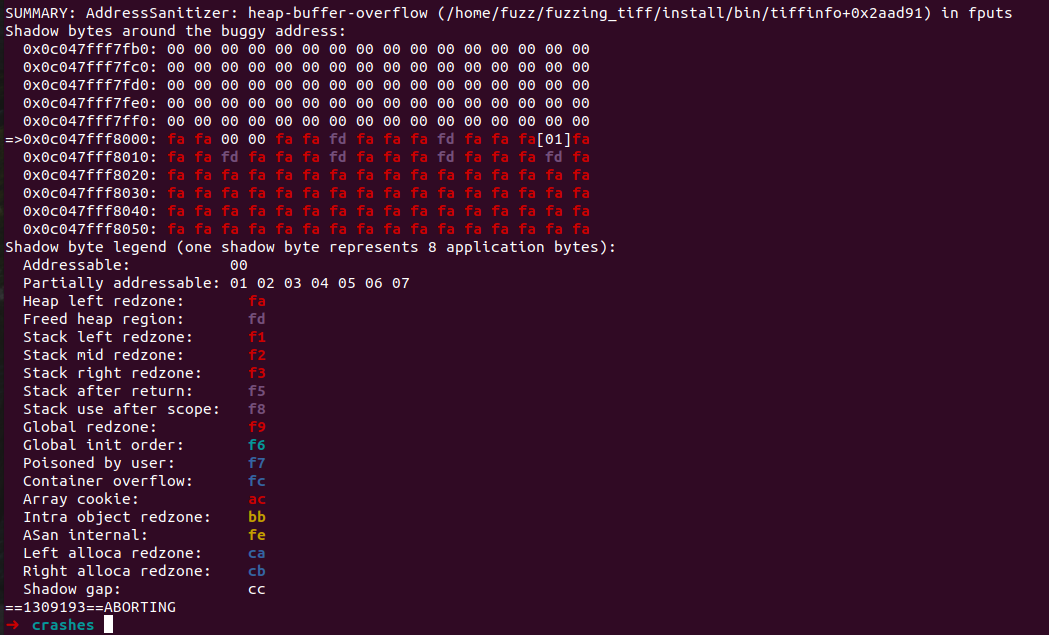
可以发现越界出现在这里[01]位置,也就是我们只能写这里的一个byte。而这个地方位于fa和fa之间,应该是申请的堆空间,产生了越界写。
调试分析
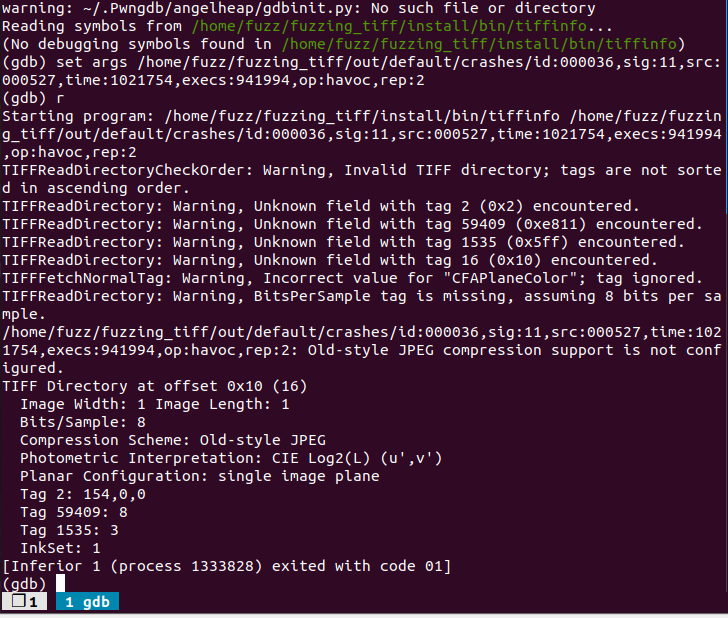
太麻烦了,使用了ASAN之后似乎crash都没有用了。直接gdb调试起来会退出,不知道哪位师傅知道为什么?
使用lcov进行覆盖率分析
之前介绍了c语言中的gcov工具,这里用的是lcov,两者有什么区别呢?lcov是gcov的前端工具
一般而言,使用lcov的方法在上面也写了。就是编译程序的时候(gcc *)加上-fpro-file-arcs和-ftest-coverage。然而我们要生成configure文件,不是直接调用的gcc,而是使用makefile。那么就只能在configure的时候加上”-coverage”
1 | CFLAGS="--coverage" LDFLAGS="--coverage" ./configure --prefix="$HOME/fuzzing_tiff/install/" --disable-shared |
参考链接学习了lcov的用法。简要记录在下面
1 | 将文件夹内所有.da文件删除 |
我选择了前十个崩溃的样本,得到如下结果。
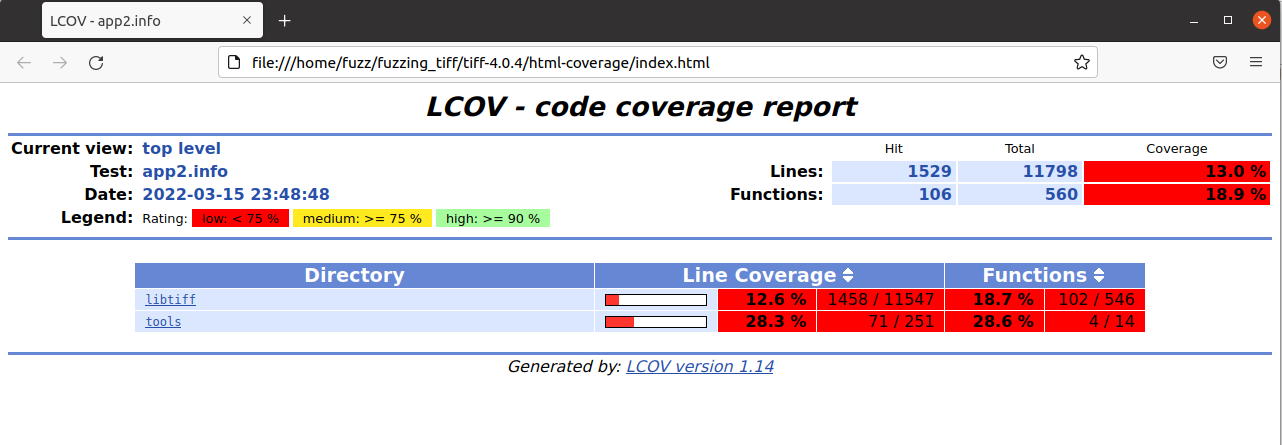
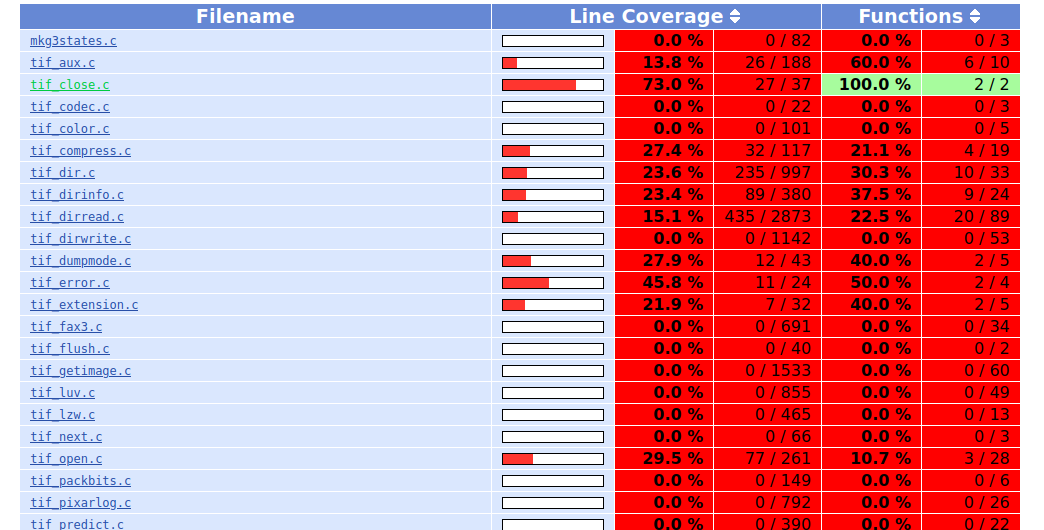
甚至连源码的哪一行可以被执行到都列出来了,这个工具tql
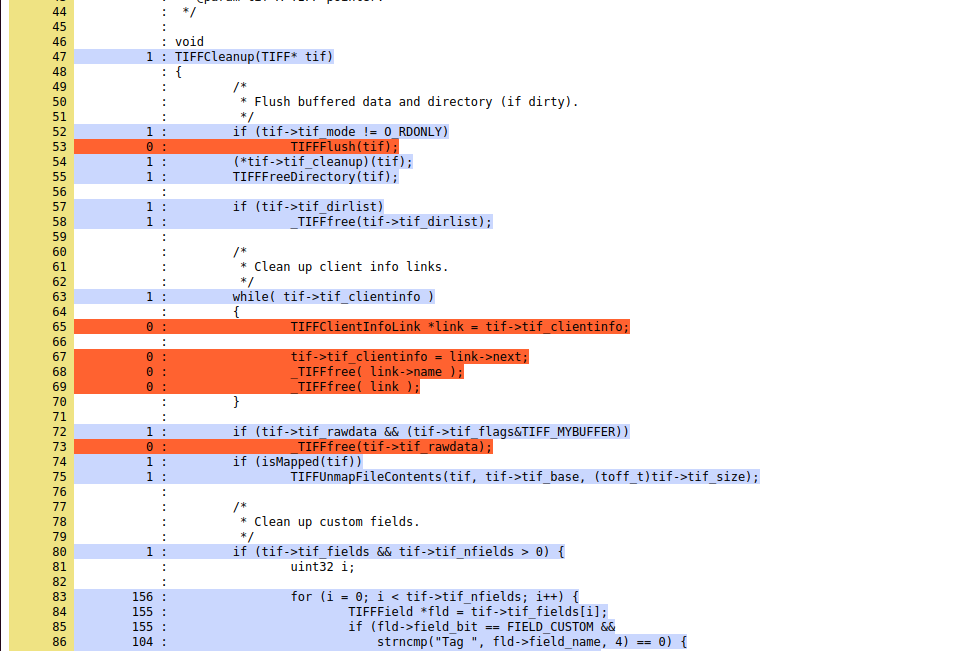
使用的命令是就是以上的命令。在fuzzing101中的最后一步使用了一个--no-checksum,查看文档。
1 | --checksum |
最后我写了一个脚本,把所有poc全部执行一遍(这里用的是相对路径,本batch文件放在tiff-4.0.4文件夹中)
1 | cd ../out/default/crashes/ |
可以看到运行poc代码中的覆盖面确实相对而言多了一点(相比于之前的)
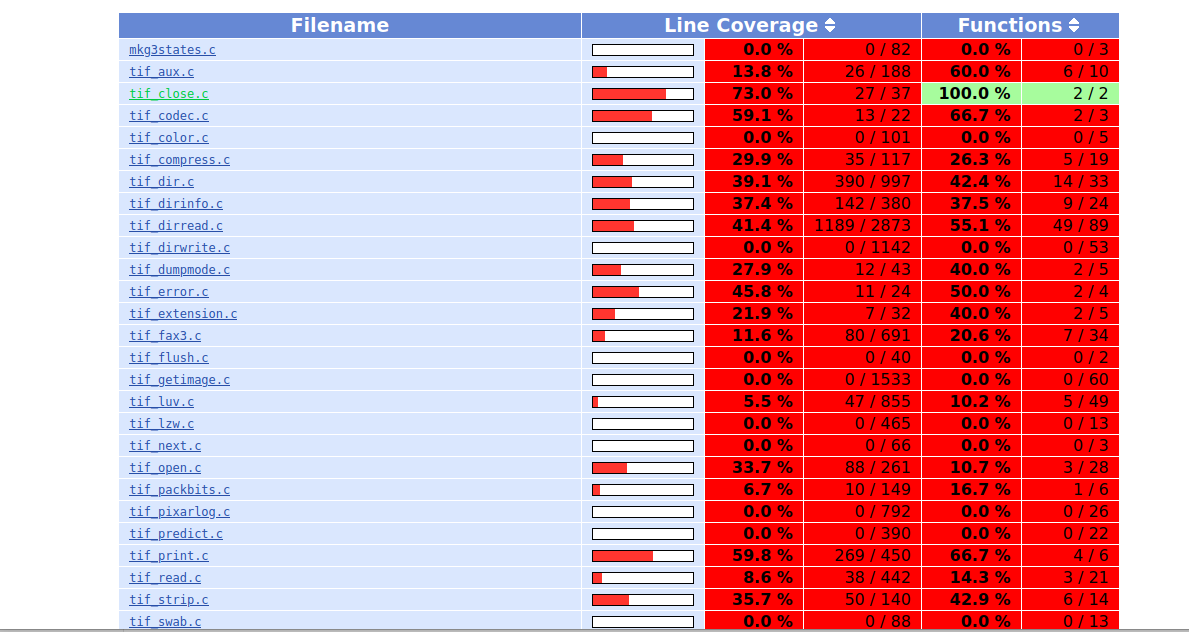
总结
学到了代码覆盖面的衡量标准,通过python的systrace能够编写简单的trace程序。使用gcc原生gcov和locv创建可视化代码覆盖面图表。使用afl结合ASAN输出代码漏洞(这里弥补了练习3中我至今没有跑出来的漏洞,发现ASAN工具能够直接给出问题,但是似乎不能调试)总的来说,是关于代码覆盖面如何测量、计算的一个比较全面的学习。