本次测试对象是LibXML2,目的是发现CVE-2017-9048漏洞。此外,还有fuzzingbook中关于mutation相关知识的学习。
fuzzingbook
链接一开始说明了一个问题,就是纯随机的变量输入可能要经过非常非常长的时间才能得到一个可能让我们控制流走得更深入的一个输入。(思考一个http://开有的字符串,如果用纯随机,时间将会非常非常漫长)
变异类型
一开始,介绍了一些常见的变异类型。包括
- 随机删除一个字符
- 在随机位置插入一个随机的字符
- 将一个随机位置的字符异或上一个随机字符(注意后面这个随机字符一般必须使得异或之后结果还是可见字符)(英文叫flip)
对于一般的变异类型,如果我们递归的加上新的变异种类,可能得到其他结果。此外,如果叠加了变异次数,也可能得到更多的优秀的变异结果。我们可以创建一个简单的mutationfuzz类,其作用是变异当前的输入,并且在当前输入(seed)用完的情况下,生成新的candidate。
1 | class MutationFuzzer(Fuzzer): |
可以用以下内容生成新的candidate
1 | class MutationFuzzer(MutationFuzzer): |
接着,我们就可以直接调用以下的fuzz()来生成一系列变异的输入。
1 | class MutationFuzzer(MutationFuzzer): |
用覆盖率引导变异
这也是变异中非常需要关注的,如何用程序的结构来引导变异。这样可以增加代码覆盖面积。
fuzzingbook中,使用了一个和AFL十分相近的引导方法——如果覆盖率增加了,就说明这次变异产生了良好的效果。可以使用python自带的coverage库实现对代码覆盖面的评估。
==但是这里找了很久,也没有找到fuzzingbook中关于coverage()方法返回值的说明?==也就是下面一行

不太清楚第返回值的每一个元组中二个参数的含义是什么。
我们循环运行一个程序,每当coverage没有出现在当前集合中时,就输出这样的输入。因为这样的输入产生了新的路径。
fuzzing101环境
LibXML2安装,编译
1 | wget http://xmlsoft.org/download/libxml2-2.9.4.tar.gz |
上网查看一下这个库的作用是什么。大致是一个xml库的命令行处理工具。
The xmllint program parses one or more XML files, specified on the command line as
XML-FILE(or the standard input if the filename provided is - ). It prints various types of output, depending upon the options selected. It is useful for detecting errors both in XML code and in the XML parser itself.
Dictionaries
当我们要fuzz的程序是文本相关的时候,给fuzzer提供一个包含一列基本参数信息的字典是很有帮助的,fuzzer可以用这个来对当前内存中的文件做一些修改,具体而言,包括替换和插入。
AFL++官网给我们提供了一系列字典,链接。给fuzzer提供-x参数即可指定dictionaries的位置。
并行
在多核系统上,开启多个fuzzer能够最大化的并行程序。由于AFL使用的是不确定的算法,因此我们只要随机运行多个AFL,就能得到不同的变异结果等。但是如果指定了seed,需要确保seed两两不相同。可以看出afl的不确定性算法就是依赖于seed的随机性。
AFL 多核fuzz官方文档。可以看到我们必须为每一个fuzzer创建一个名字,无论是master还是slave。其次,他们必须共享一个out文件夹。一般而言,子fuzzer需要满足以下要求。
第一项就是之前了解过的ASAN
第二项和控制流分支中的数据处理相关。fuzzer可以在数据被比较之前修改它,达到覆盖更多控制流。
第三项和第二项列在一起,主要是将整数、字符串、浮点数和switch等等分开,单独拿出来变异等,让AFL能够更全面的解决分支处理。
AFL有两种并行方式,独自生成和共享份额。独自生成前一段讲述的内容,共享份额是fuzzer从所有别的fuzzer输出的信息中中获取别的testcase。
除此以外,fuzzer之间还可以并行联合。在上面的链接中也有提到。
命令
使用以下两个命令启动AFL。可以看到slave进程不需要设置 -x (是为了对比?还是不用设置呢)
1 | 启动master进程 |
但是,在经过了将近24小时的fuzz之后,我仍然没有找到crash,最终还是放弃了。
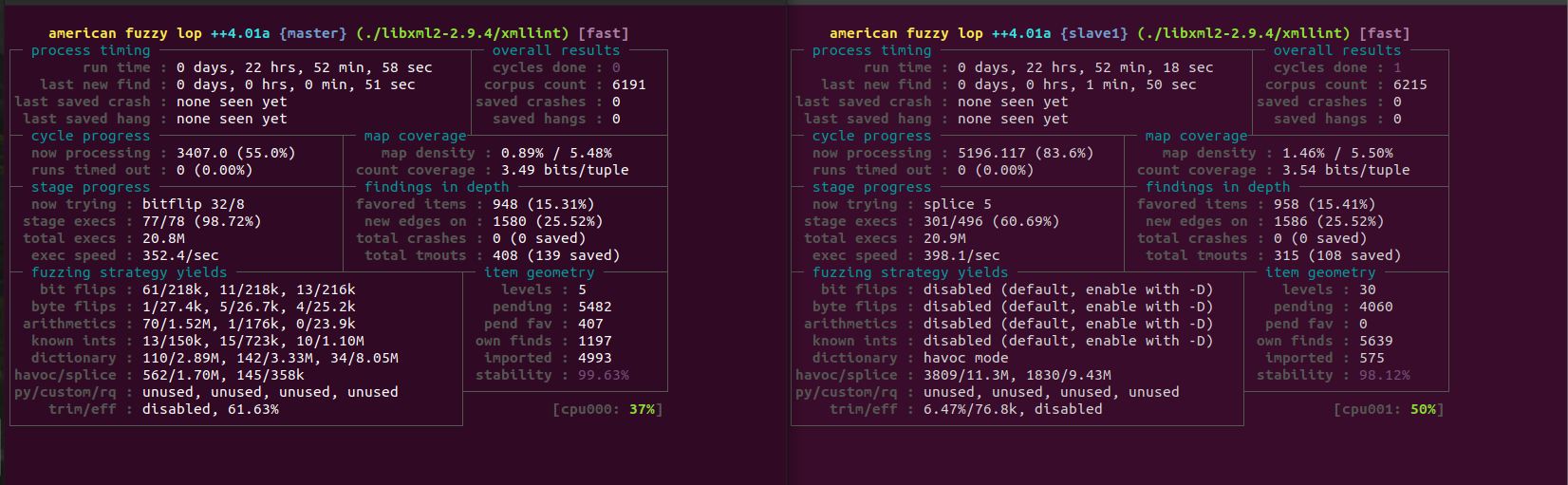
总结
在fuzzingbook中,通过python的几个例子,学到了变异的基本原理——随机删除or插入or异或新的数值产生相比于当前输入有所不同的其他输入。在这之后,了解到了如何通过代码覆盖面来引导变异,也就是如果发现了新的运行分支,就把当前的输入保存下来,后续进一步变异。
在fuzzing101中,学会了怎么对文本处理型的binary进行fuzz(加上-x参数)以及如何并发的fuzz多个程序(利用-S选项)虽然并没有得到结果,但是也收获良多。