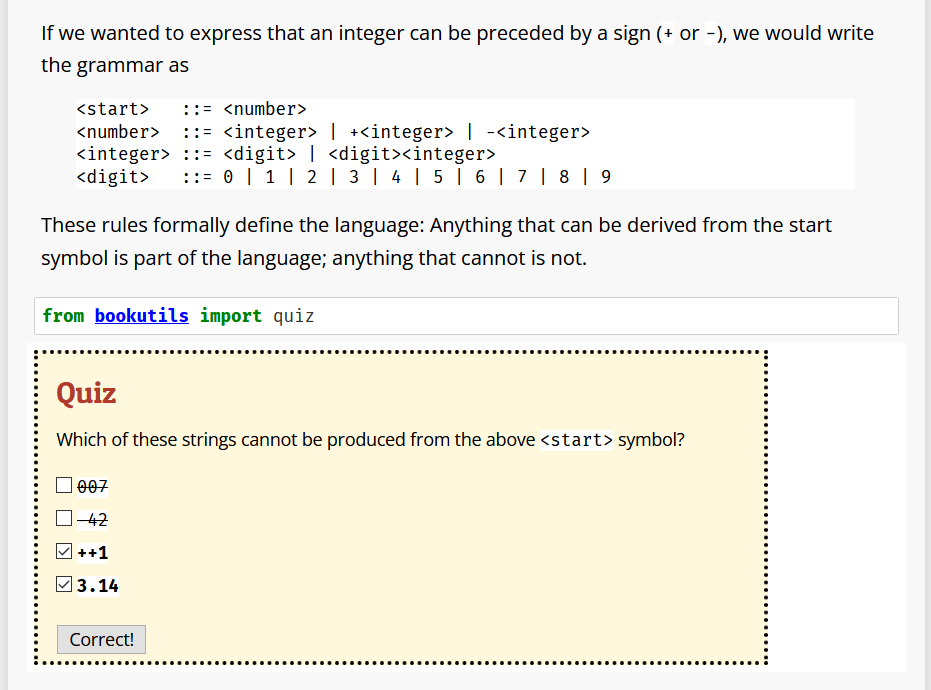
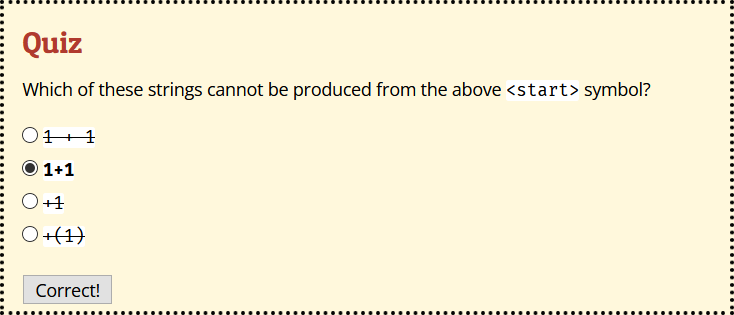
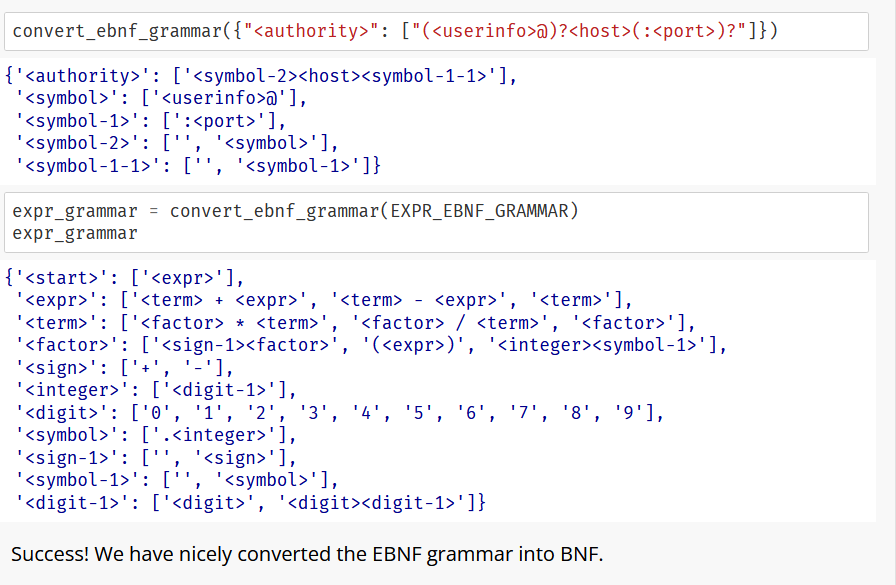
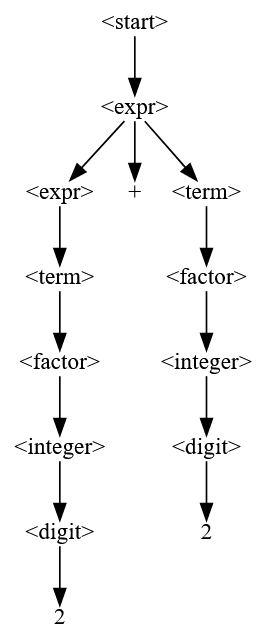
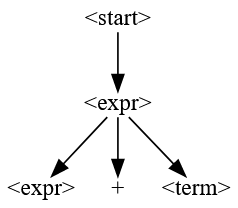
To read such a grammar, start with the start symbol (<start>). An expansion rule <A> ::= <B> means that the symbol on the left side (<A>) can be replaced by the string on the right side (<B>). In the above grammar, <start> would be replaced by <digit><digit>
defsimple_grammar_fuzzer(grammar: Grammar, start_symbol: str = START_SYMBOL, max_nonterminals: int = 10, max_expansion_trials: int = 100, log: bool = False) -> str: """Produce a string from `grammar`. `start_symbol`: use a start symbol other than `<start>` (default). `max_nonterminals`: the maximum number of nonterminals still left for expansion `max_expansion_trials`: maximum # of attempts to produce a string `log`: print expansion progress if True"""
term = start_symbol expansion_trials = 0
# 当术语中还有非终止符号的时候 whilelen(nonterminals(term)) > 0: # 从术语中所有非终止符中挑选一个扩展。这里和之前讲的有顺序的扩展不太一样。 symbol_to_expand = random.choice(nonterminals(term)) # grammar是之前我们写的map类型的规则,作为参数传递进这个类,在这里引用,并找到这个key对应的expansion种类。 expansions = grammar[symbol_to_expand] # 从这个key的所有expansion中随机找到一个 expansion = random.choice(expansions) # In later chapters, we allow expansions to be tuples, # with the expansion being the first element ifisinstance(expansion, tuple): expansion = expansion[0] # 将随机选取的扩展替换之前的 new_term = term.replace(symbol_to_expand, expansion, 1) # 这里是防止非术语过多导致爆栈问题。设置了一个非术语数量上限。如果小于上线,就将术语替换成刚才换掉的,否则expansion_trials++,表示超出一次。如果超出多次,就直接停止计算。 iflen(nonterminals(new_term)) < max_nonterminals: term = new_term if log: print("%-40s" % (symbol_to_expand + " -> " + expansion), term) expansion_trials = 0 else: expansion_trials += 1 if expansion_trials >= max_expansion_trials: raise ExpansionError("Cannot expand " + repr(term))
TITLE_GRAMMAR: Grammar = { "<start>": ["<title>"], "<title>": ["<topic>: <subtopic>"], "<topic>": ["Generating Software Tests", "<fuzzing-prefix>Fuzzing", "The Fuzzing Book"], "<fuzzing-prefix>": ["", "The Art of ", "The Joy of "], "<subtopic>": ["<subtopic-main>", "<subtopic-prefix><subtopic-main>", "<subtopic-main><subtopic-suffix>"], "<subtopic-main>": ["Breaking Software", "Generating Software Tests", "Principles, Techniques and Tools"], "<subtopic-prefix>": ["", "Tools and Techniques for "], "<subtopic-suffix>": [" for <reader-property> and <reader-property>", " for <software-property> and <software-property>"], "<reader-property>": ["Fun", "Profit"], "<software-property>": ["Robustness", "Reliability", "Security"], }
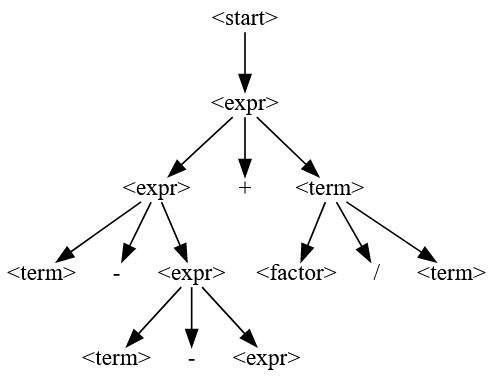
结果如下,解释方式其实上面计算器的例子已经很好的说明了。
1 2 3 4 5 6 7 8 9 10
{'Fuzzing: Generating Software Tests', 'Fuzzing: Principles, Techniques and Tools', 'Generating Software Tests: Breaking Software', 'Generating Software Tests: Breaking Software for Robustness and Robustness', 'Generating Software Tests: Principles, Techniques and Tools', 'Generating Software Tests: Principles, Techniques and Tools for Profit and Fun', 'Generating Software Tests: Tools and Techniques for Principles, Techniques and Tools', 'The Fuzzing Book: Breaking Software', 'The Fuzzing Book: Generating Software Tests for Profit and Profit', 'The Fuzzing Book: Generating Software Tests for Robustness and Robustness'}
classGrammarFuzzer(GrammarFuzzer): defchoose_tree_expansion(self, tree: DerivationTree, children: List[DerivationTree]) -> int: """Return index of subtree in `children` to be selected for expansion. Defaults to random.""" return random.randrange(0, len(children))
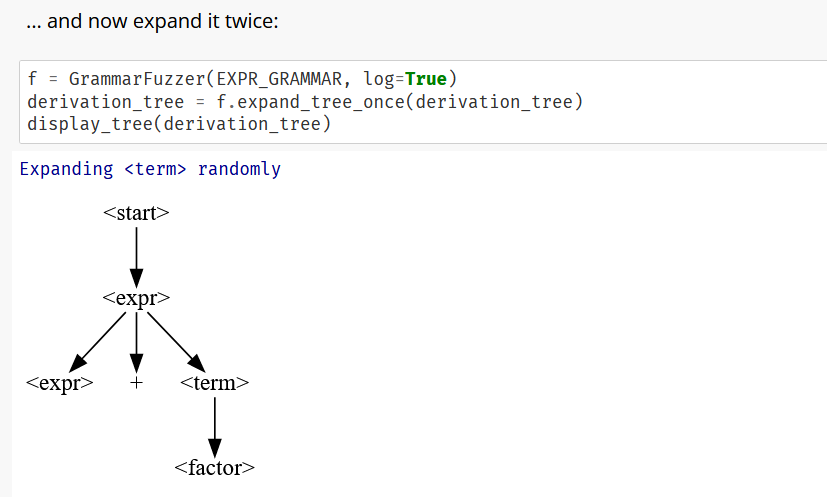
defexpand_tree_once(self, tree: DerivationTree) -> DerivationTree: """Choose an unexpanded symbol in tree; expand it. Can be overloaded in subclasses.""" (symbol, children) = tree if children isNone: # Expand this node return self.expand_node(tree)
# Find all children with possible expansions expandable_children = [ c for c in children if self.any_possible_expansions(c)]
# `index_map` translates an index in `expandable_children` # back into the original index in `children` index_map = [i for (i, c) inenumerate(children) if c in expandable_children]
# Select a random child child_to_be_expanded = \ self.choose_tree_expansion(tree, expandable_children)
# Expand in place children[index_map[child_to_be_expanded]] = \ self.expand_tree_once(expandable_children[child_to_be_expanded])
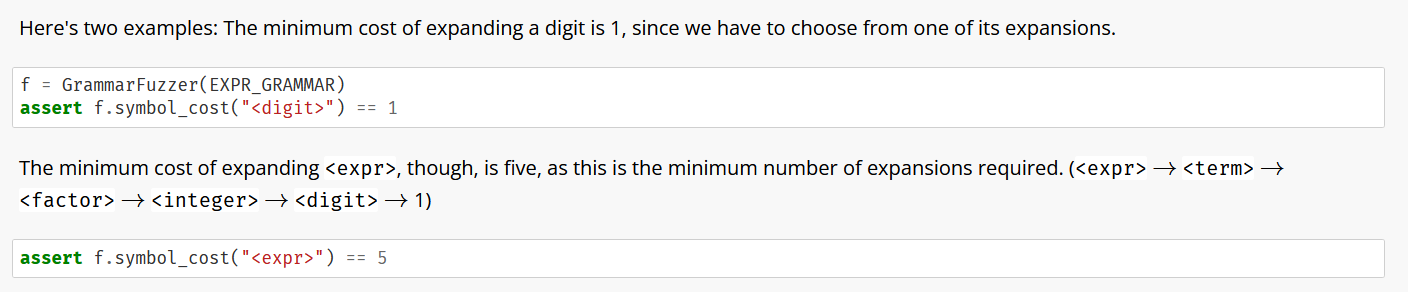
Max cost expansion. Expand the tree using expansions with maximum cost until we have at least min_nonterminals nonterminals. This phase can be easily skipped by setting min_nonterminals to zero.
Random expansion. Keep on expanding the tree randomly until we reach max_nonterminals nonterminals.
Min cost expansion. Close the expansion with minimum cost.