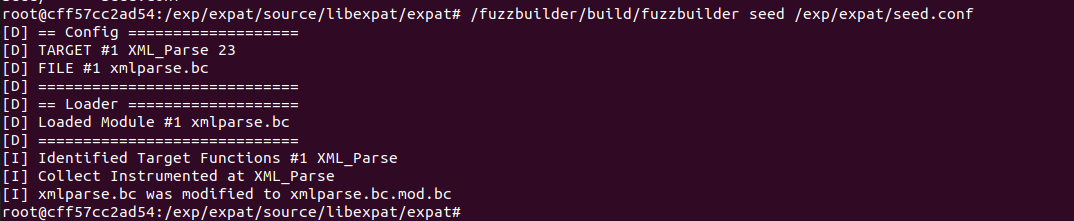
更新中…
启动docker命令:sudo docker exec -it c_ares_FB /bin/bash
读取文件
这里比较关键的是构建target。在parse_conf里面,经过了一系列错误判断,最终落入本函数中。
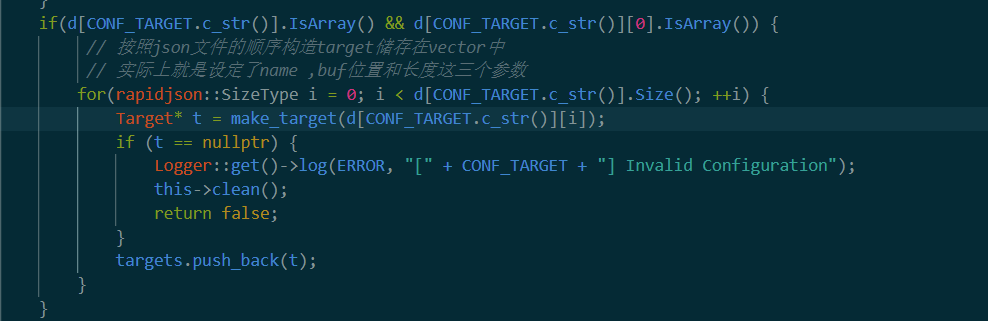
这里最后有一个target全局变量。打开make_target可以看到其实是把用来描述target的文件作为json文件读取,然后放在一个vector中。放入的格式是(name,fuzz,len)。第一个参数是函数名,第二个是buffer在第几个参数的位置,第三个是buffer的长度。
exec部分

这里代表了参数是exec时,fuzzbuilder会做的事情。main中调用了Execgen::generate,其代码如下。
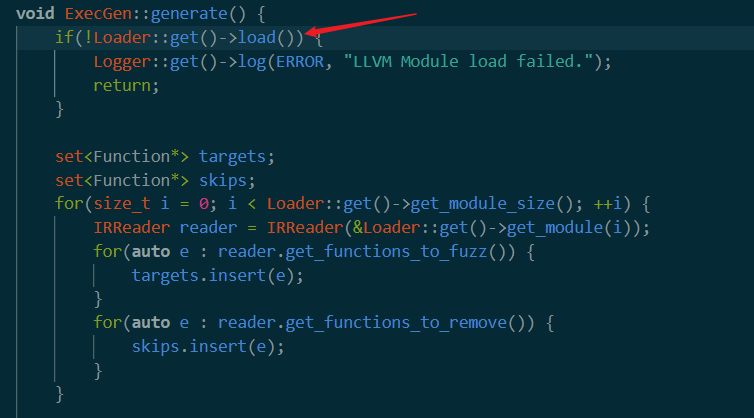
首先,函数调用load(),把之前json格式的数据加载进来。
load file
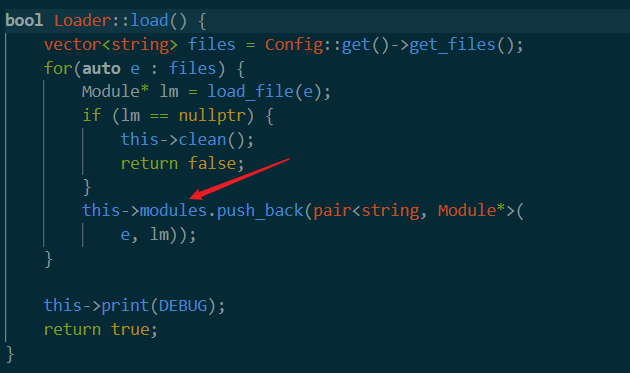
这里引入了一个新的属性,this->modules。这是一个记录了所有file和Module*格式的文件的一个vector。这里的get_files()和Module*类型的文件留到后面分析。只需要知道这里把文件和对应的模块都放到一个vector中即可。
循环 in generate
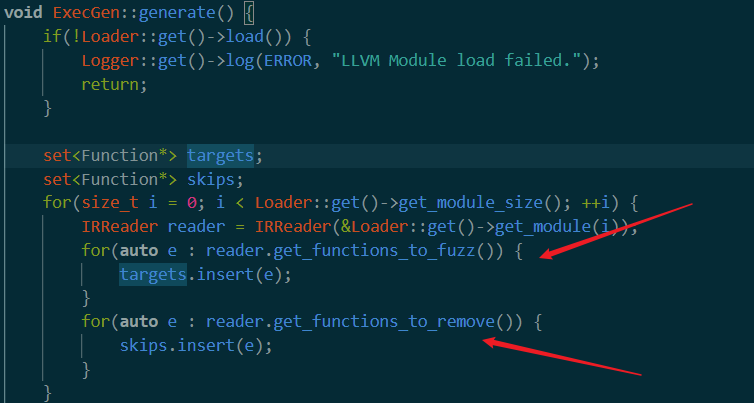
接着的循环,首先读取module_size也就是刚才load进来的module vector的大小。接着get_module返回每一个vector的第二个参数,也就是push进来的module类型变量。这是一个IRREADER类型的数据。我们看看这个类型是什么。
IRReader
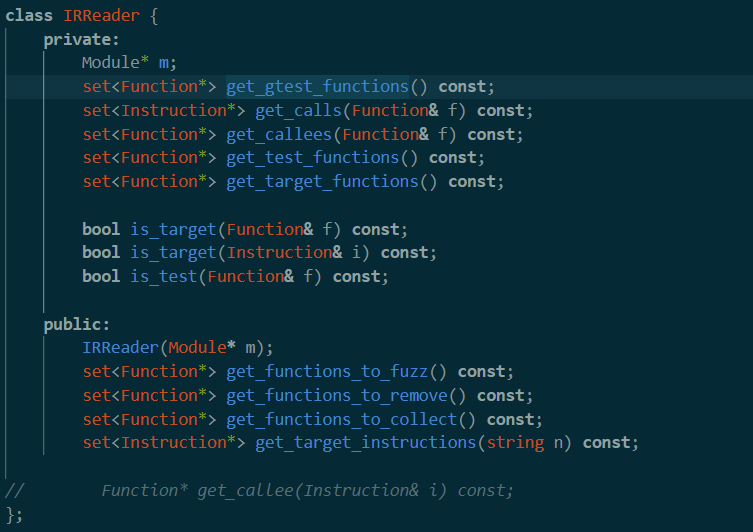
重点看到这里的构造函数。不过打开一看,也就是简单赋值。

后面我们用到了其中的两个函数,一个是get_functions_to_fuzz(),另一个是get_functions_to_remove。现在提前来看看。
get_functions_to_fuzz
首先是获得要被fuzz的函数。期间还做了一些检查,但是没看明白。里面有一个test变量,不知道是什么意思。返回了一个ret用来储存所有的要被fuzz的函数。
接下来有一个is_target的判断。如果是就把该函数push到tmps向量中。这里的ret是上面get_test_functions的返回值。
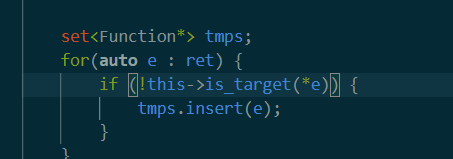
这里的is_target很有意思。大概作用是先获得所有target函数名。(关于target定义写在读取文件部分)之后获取参数函数的所有调用的函数,然后一旦找到调用函数name和target相同就返回true,表示该函数是一个有效的target。为什么要这样做? 为了看看当前要被测试函数的调用的函数中,是否有我们需要的target。回顾一下,targets是target function,而这里的形参f是外面的ret,也就是test_func。
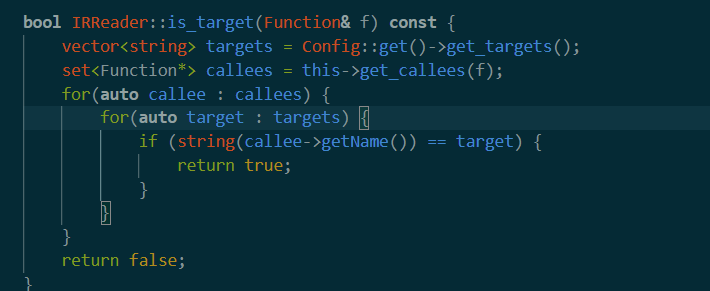
这里两者的不同需要澄清。看到他给的示例文件。所谓target就是目标要fuzz的函数,test所指示的可能是所有可能的能够找到上述调用target函数的集合开头(不必写全,因为可以看到后面是字符串比较)。因此上面这段代码的用途就清楚了:在下面这张图中test开头的所有函数里,找调用target的函数如果找到不包含target的test_开头的函数,就把函数名称返回出来。(这样做看似很奇怪)
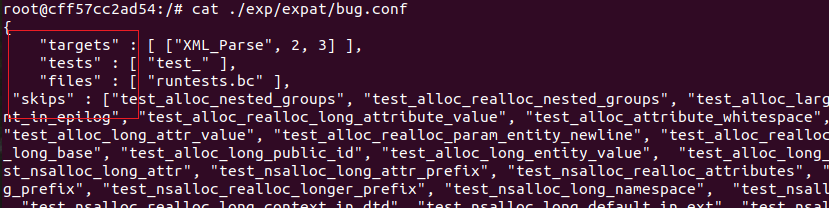
但是看到这里就清楚要干啥了。
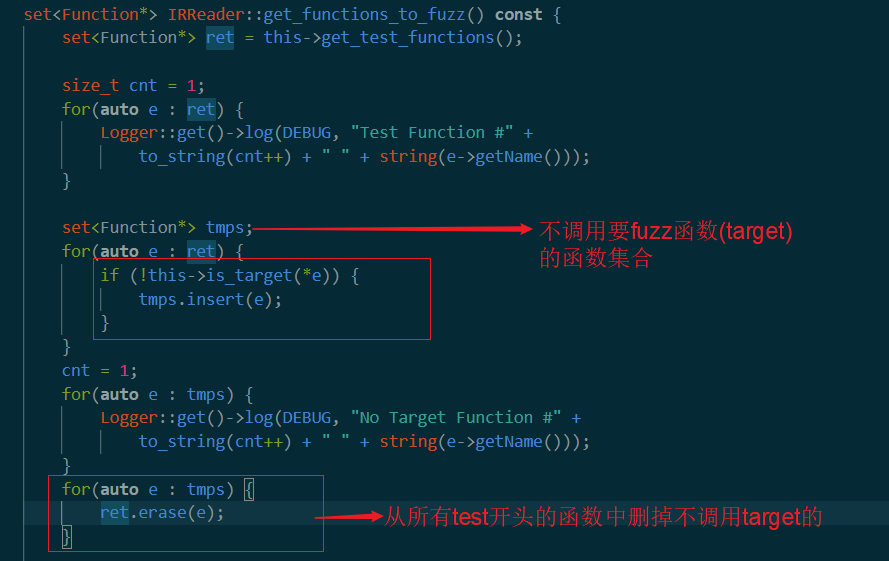
==这里有一个没分析的get_callees==,比较复杂后面再看。
同样的,下面一半是获得skips的函数。这里就比较清晰。 获取skip的函数,并从ret中删掉这些函数。获得去除不调用target函数以及在skip集合中的函数之后的函数集合ret
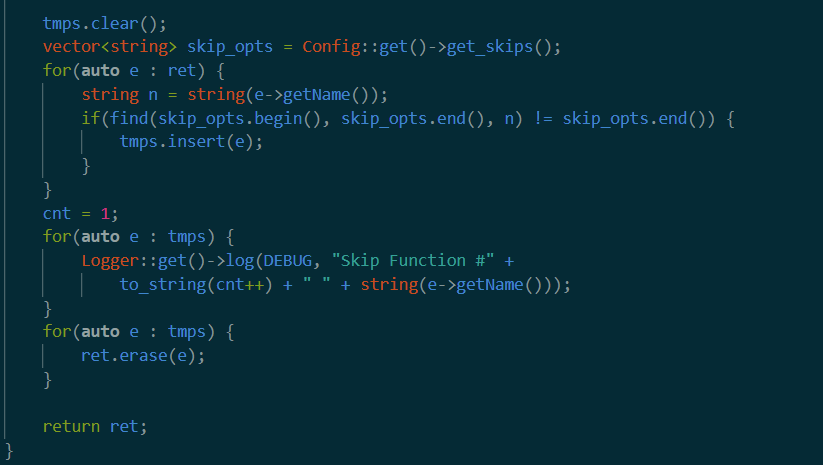
回到外部
(接着上面的 循环 部分)
接着再循环里面看到第二个get_functions_to_remove函数。
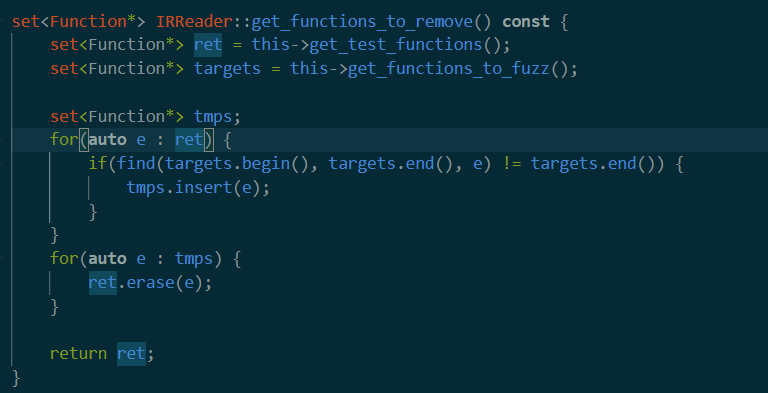
这个操作感觉很傻,大致意思是找到所有在_test开头文件中并且没有调用target的。这里都用的是vector的比对操作。
因此,两个操作,为了确保找到fuzz的函数的调用函数,并且确保这些函数是”test”规则开头的函数,并且不在skips列表里面。
在一顿report之后,到了这里
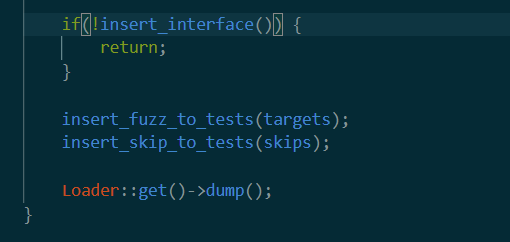
insert interface
重点看以下两个函数。
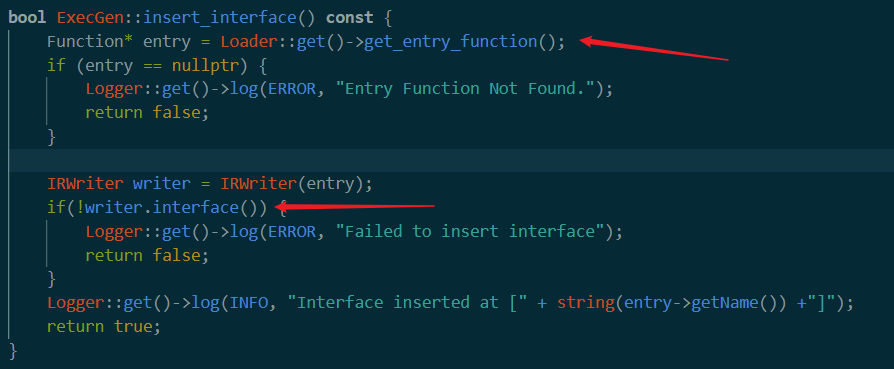
get_entry_function
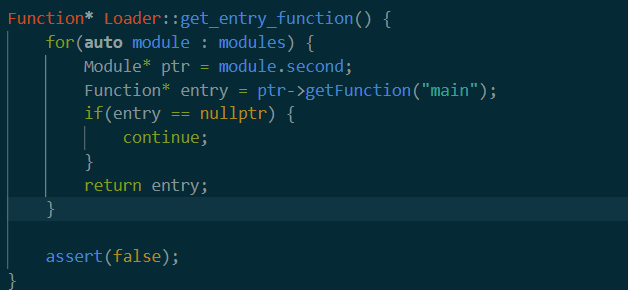
用到了之前提到的module。每一个module是一个<file,module>的二元组。可以看到这里是用了module的getFunction方法。

这里又牵涉到module的概念。

我觉得可以理解为每一个ELF文件的文件头部信息?
回到上面的get_function。这里的意思就是从之前的module结构体中找到包含main的module,然后这个作为entry function返回。接着初始化一个IRwriter类型变量,将之前得到的main函数指针赋值到这里。

这里又牵涉到另一个类,IRwriter。后面用到的时候再分析。
==writer.interface==
这个函数及其复杂,==留到后面分析==,位于irwriter.cc中。大致看一眼发现用到了很多神奇的操作
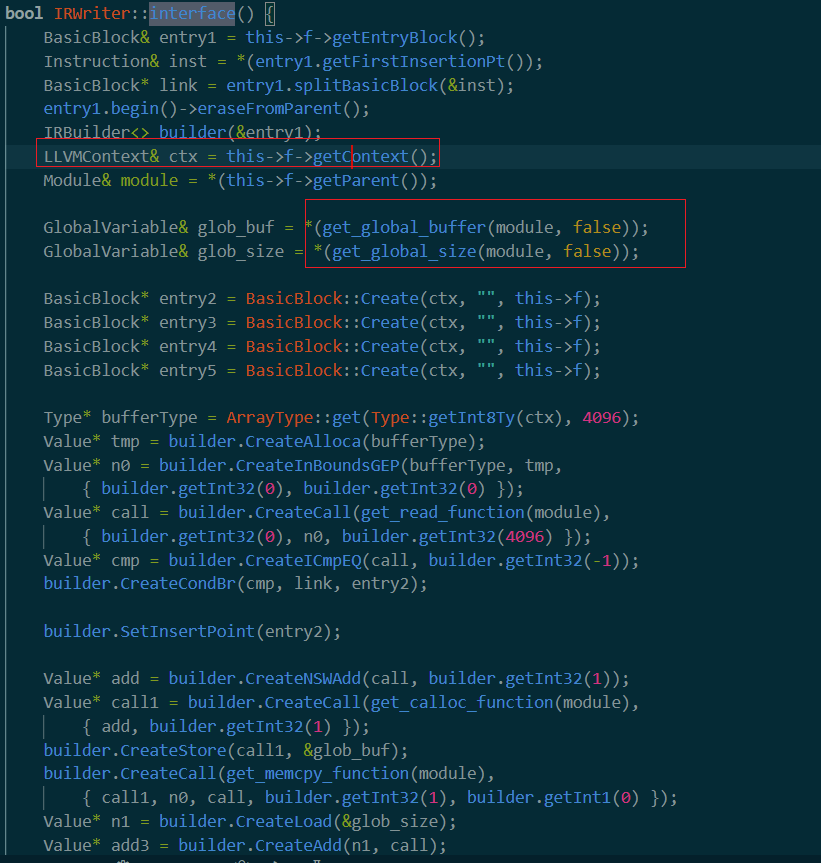
比如这里的getContext, get_global_buffer等。看起来像是为main函数设置好调用上下文。
回到外部
接下来是这三个函数
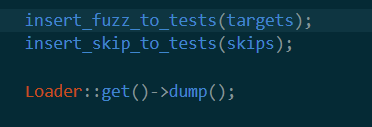
insert_fuzz_to_tests
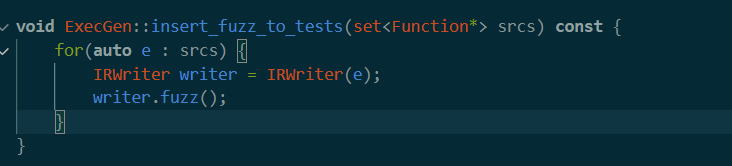
这里的srcs是之前的target,也就是所有要fuzz的函数总和。可以看到这里为每个函数初始化了一个IRwriter类型的变量,然后进入fuzz函数。于是接着看writer.fuzz()是什么意思。
writer.fuzz
重点分析下面这些函数。(好多啊)
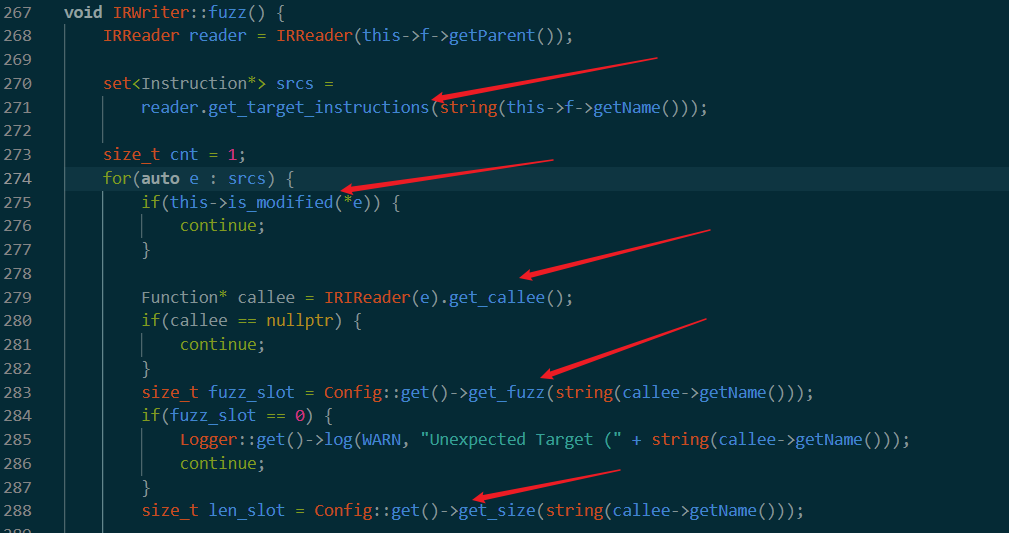
get_target_instructions
接受一个函数名作为参数
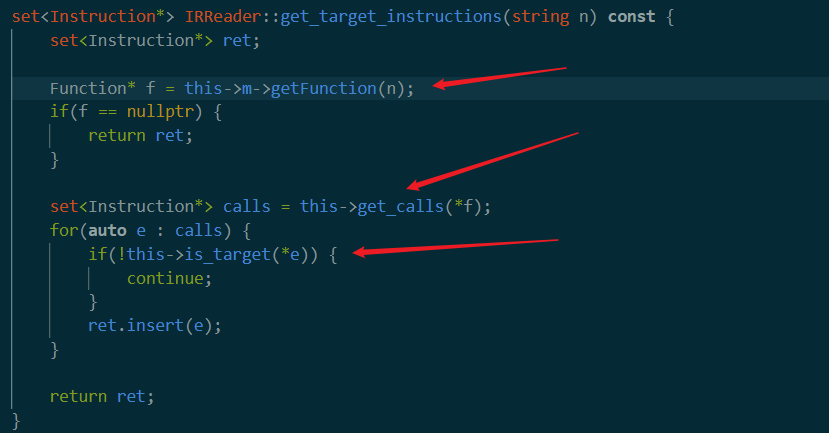
首先调用getFunction。这个没找到定义,是Module* m类型变量的成员函数。
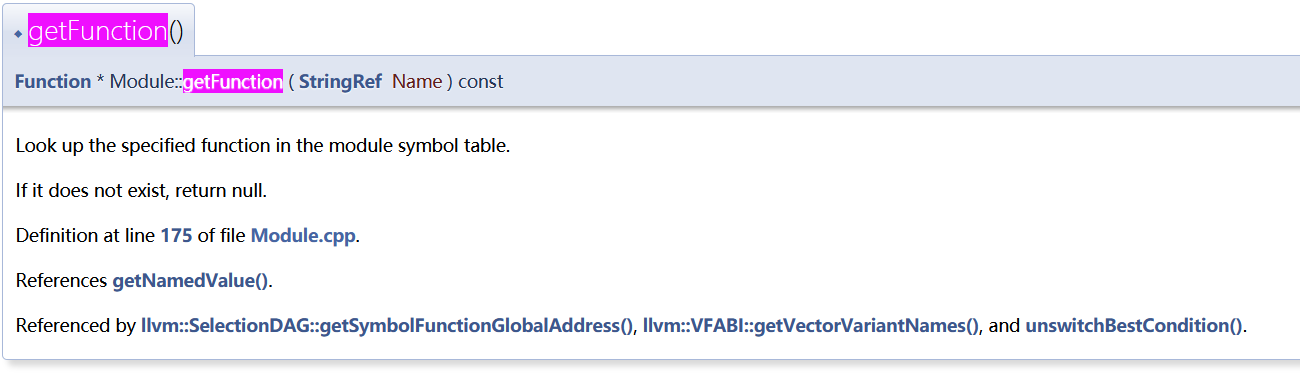
可以看到是先获得module里面是不是有参数对应的函数名,如果找到,进入下面get_calls
后面是get_calls
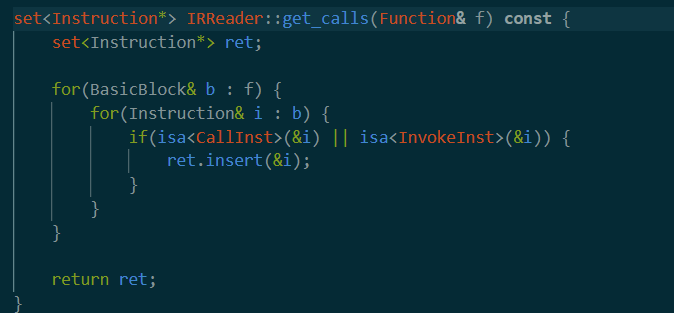
接受一个函数指针作为参数,从该函数的basicblock中,找到所有的instruction。在github上找到了相关说明。后面这句in的作用就是找到所有指令中包含invoke或者call的部分。然后插入到ret中。
之后is_target判断call的是不是目标函数。如果是就插入到集合里面返回。
is_modified
这里接受一个之前获得的instruction集合
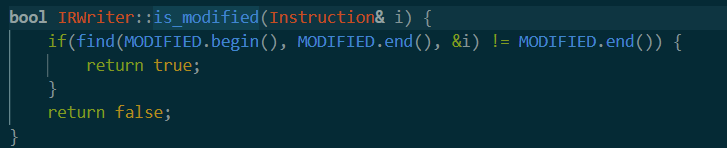
就是看MODIFIED里面有没有i这一条命令。有就返回true。这个MIDIFIED还是在writer.fuzz中找到了初始化。后面再分析。第一次调用的时候应该是空。也就是返回false。于是会直接进入get_callee
get_callee
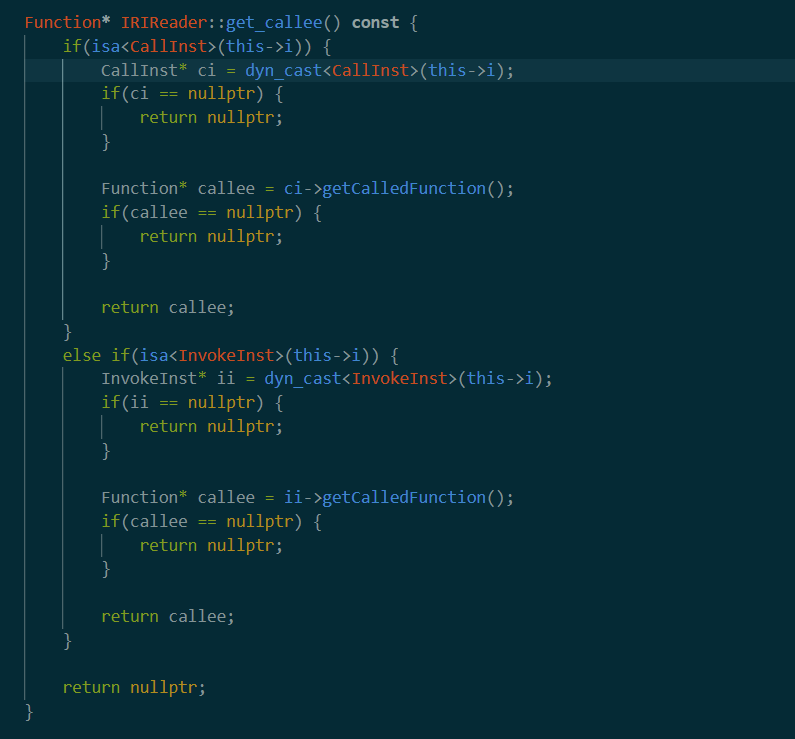
这个函数结构还是相对清晰。主要作用是找到call或者invoke调起的函数,然后返回出来。
这个操作之后返回一个callee变量(回顾一下,也就是把terget函数getparent返回的的所有函数中的所有call和Invoke的目标函数拿出来)现在callee里储存的就是所有的目标函数。
get_fuzz
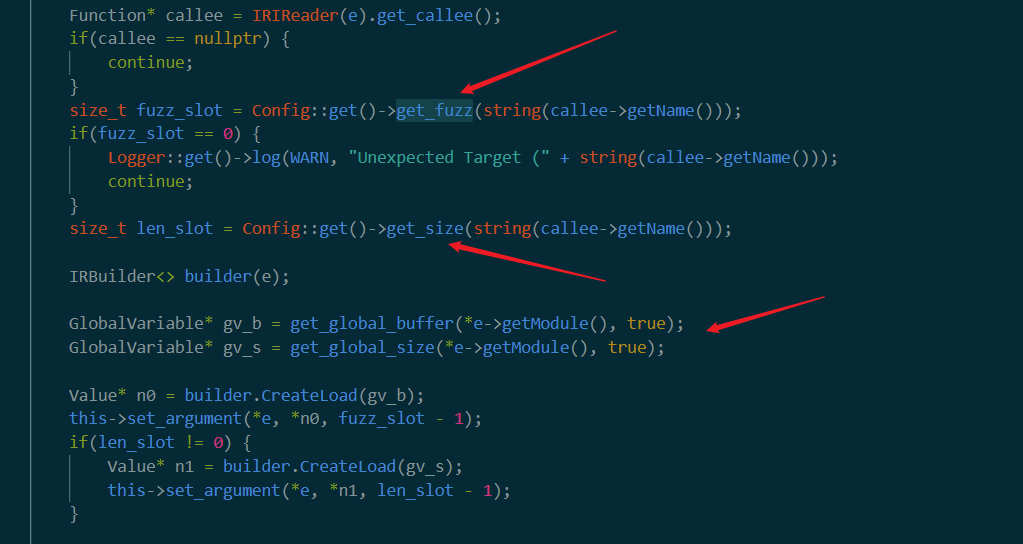
get_fuzz()接受目标函数函数名作为参数。在targets里面找到所有名字一样的函数,调用get_fuzz()。我觉得writer.fuzz到目前为止的意思就是从target函数的caller中找到所有调用target函数的语句,然后现在把这些target放到get_fuzz中。但是这里e->get_fuzz很奇怪,只能返回一个size_t类型的变量,将作为fuzz_slot返回到外部。==不知道fuzz是什么意思,或许是从参数中获取的能fuzz的参数位置吗==。现在觉得应该是的
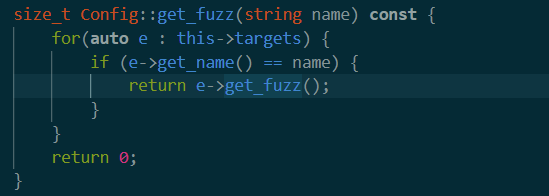

接下来有一个len_slot。初步猜测就是获得能fuzz的长度。
IRbuilder
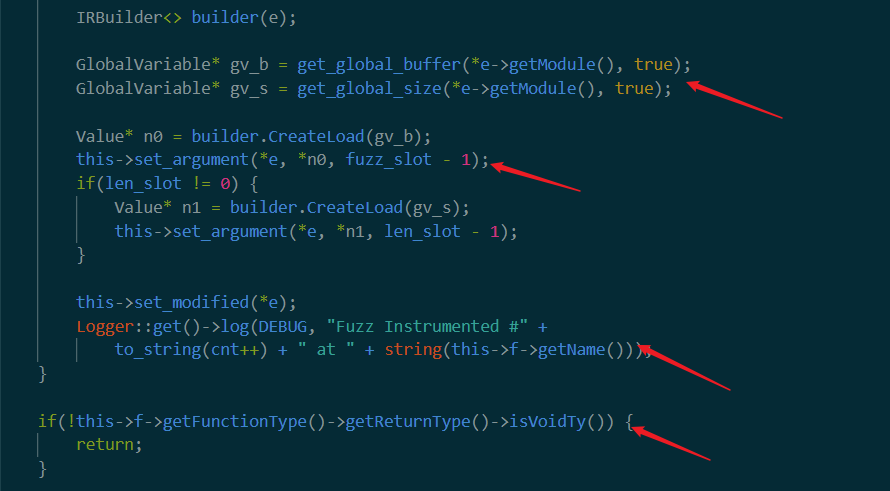
首先看到构造函数IRBuilder。在网上找到资料这个意思大概是创建一个IIVM的代码块。记住这里的e是所有调用target函数的instruction。
==get_global_buffer==
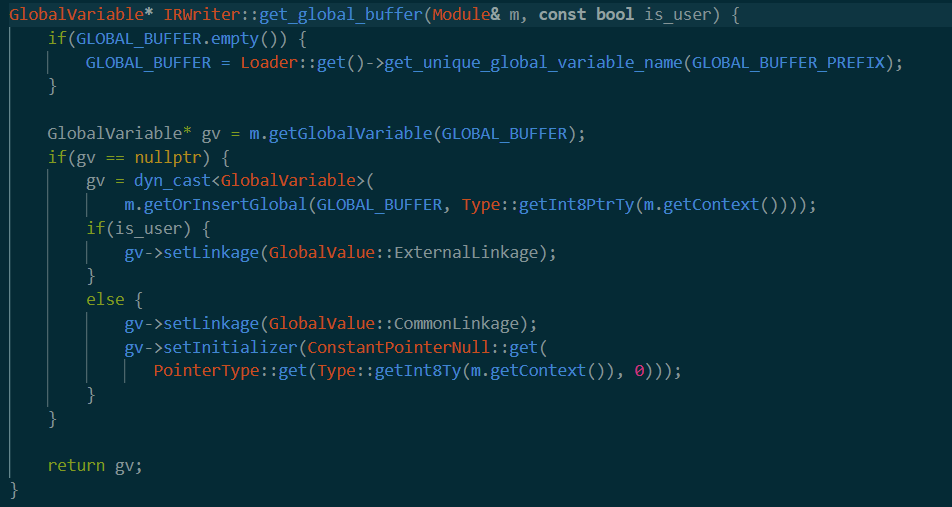
第一次进来的时候肯定是empty。进入get_unique_global_variable_name中。
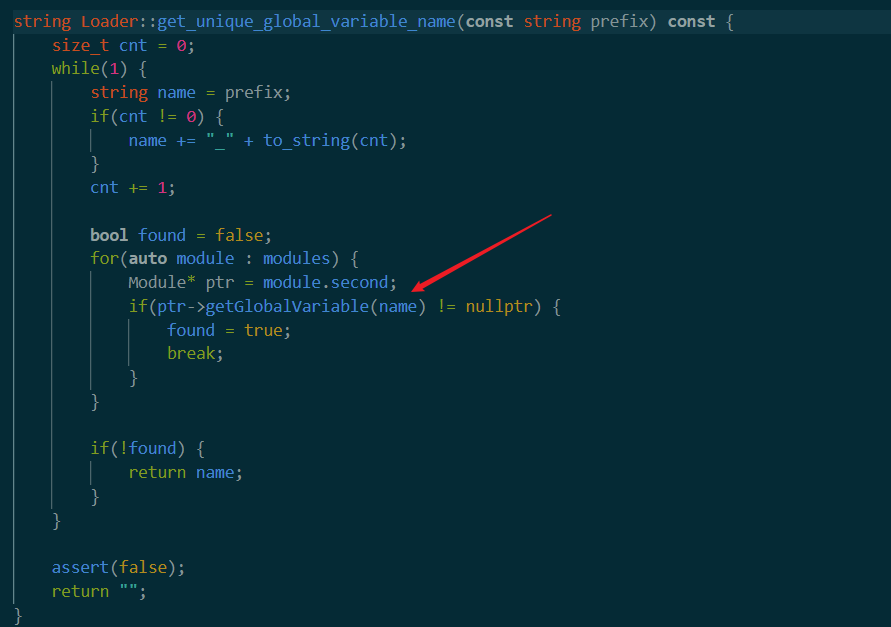
可以看到这个函数从module的第二个参数(也就是module类型变量)中尝试获取name(这里看了是fuzzbuilder_buffer_1,fuzzbuilder_buffer_2这样名字的变量),如果找到了就返回。(但是感觉应该返回空?)
于是这里gv应该返回为空。
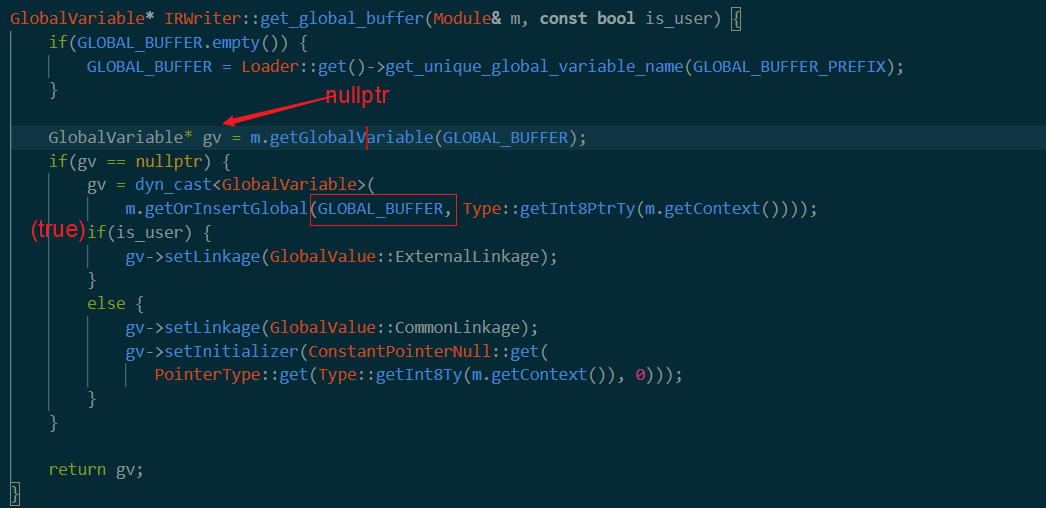
在网上查到getOrInsertglobal作用。第二个参数type是llvm特有的i8*类型,但是网上也没有说的很详细。==后面有一个setLinkage不太理解作用==。可能是把当前找到的变量和某个外部变量联系起来?
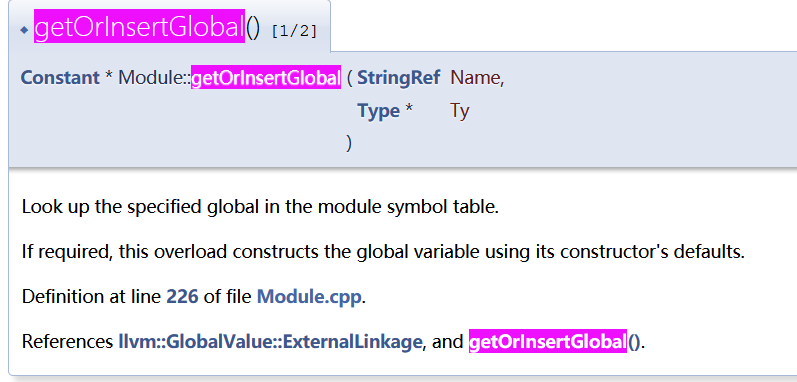
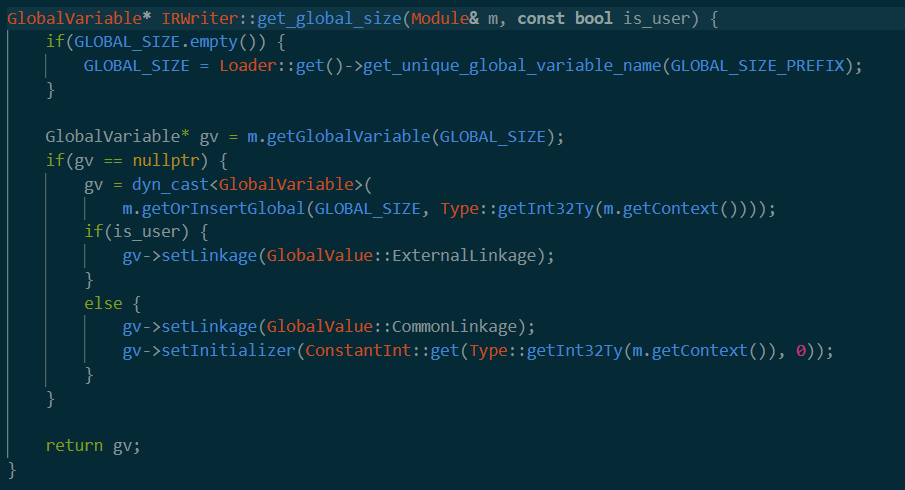
==get_global_size==
这个和上面函数长得很像。但是也是一样的问题,不太理解作用是啥。
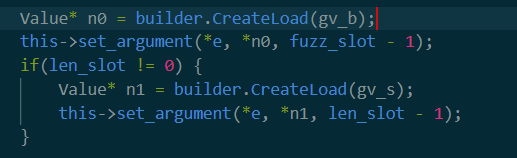
回到外部(修改调用参数)
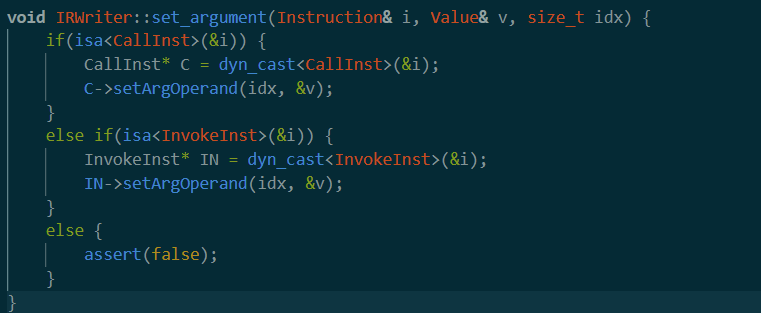
这里set_argument定义如下
可以看出这里就是关键的地方!这里把我们之前定位到的call或者invoke位置的函数设置了参数。其中idx代表参数的位置(也就是用户之前填写的),v是参数值,在这里就相当于是上面get_global_buffer返回的内容。相当于直接patch掉了原先invoke或者call的函数参数,变为我们之前创造的global buffer对象。这里就和论文的描述一致了。
这里一共patch了两个变量,分别是buffer和buffer的长度。之后把这一条语句放在modified里面

然后打出一个log表示这个调用语句已经被patch过了。
返回值处理
接下来一部分用于处理返回值。(终于快结束了)
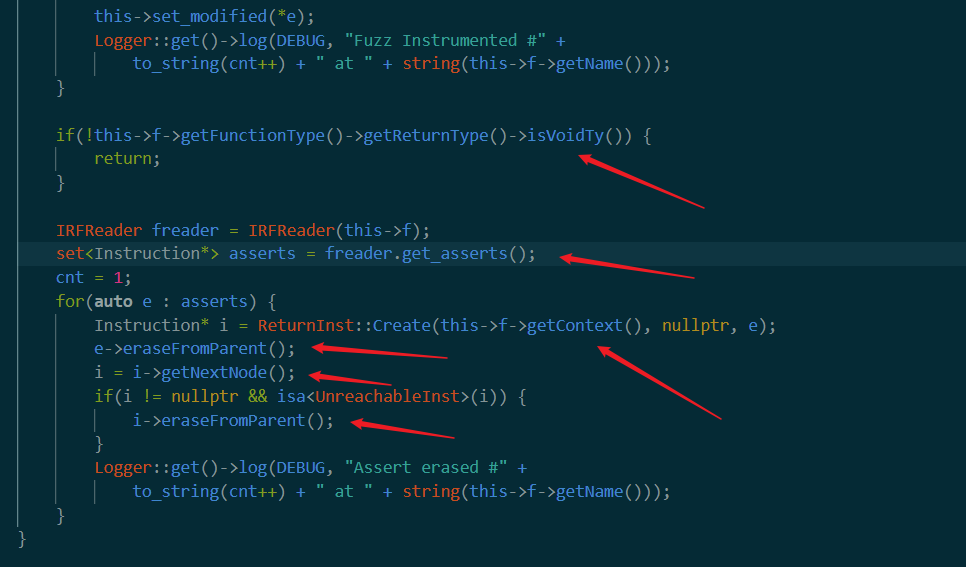
首先判断,如果返回值是void就直接过。
接着创建了一个IRFreader。这个的代码量很短
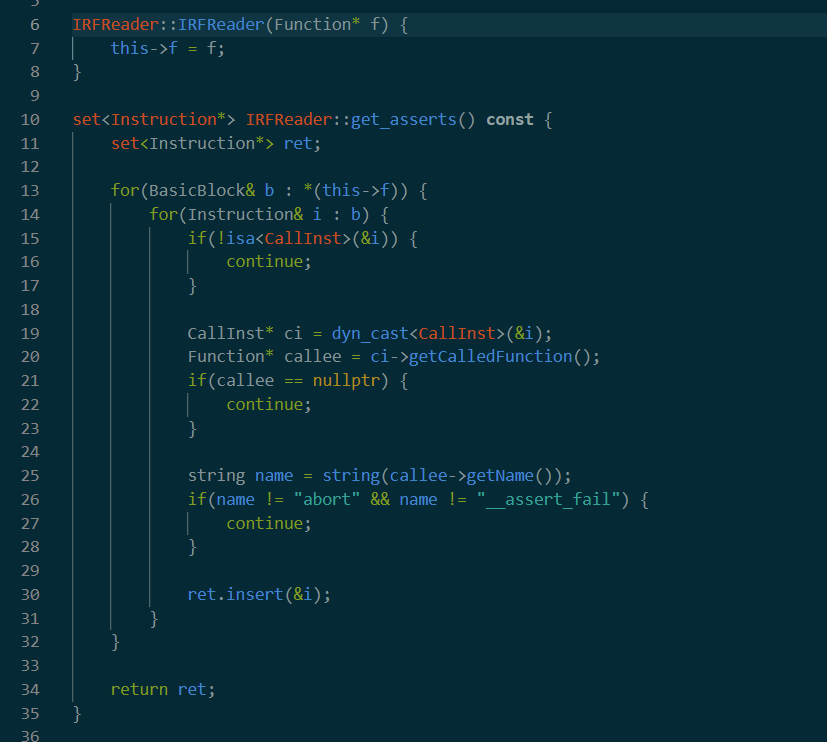
下一行就有用到get_asserts()。我们看看其含义。大概就是获得所有调用了abort和assert_fail的instruction。接着回来
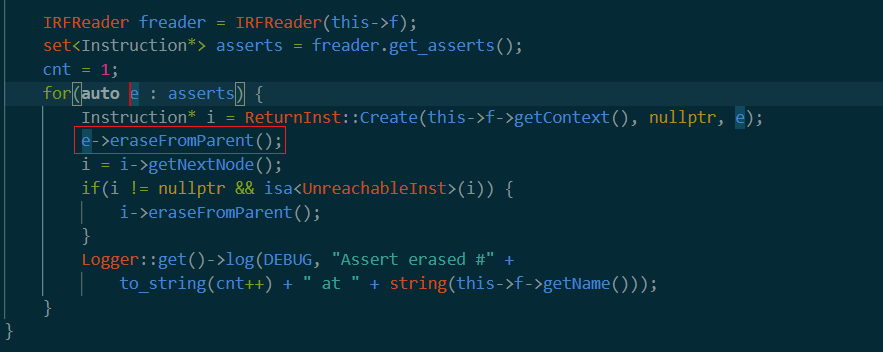
看到这里eraseFromParent应该是从调用函数这里删掉所有assert语句(个人猜测这应该是为了去除debug文件特有的assert函数来提高成功率)接着关于i的操作(这个getNextNode网上也查不到啊),大概是下一个control block?
接着判断如果i的下一个control block是可以不可达到的就删掉(我觉得大概是为了判断先把e(也就是assert语句)删掉了,确保把e删掉之后原来assert后面代码块是不可达的,这样就把他删掉)
至此,终于分析完了writer.fuzz。也就完成了对于insert_fuzz_to_test的分析。
insert_skip_to_tests
skip的处理相对简单
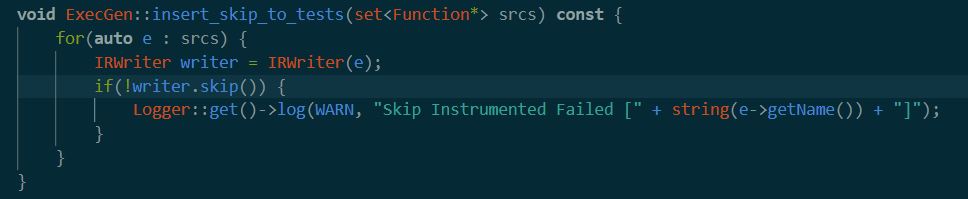
主要是writer.skip
writer.skip
下面这张图一开始的地方写错了,应该是,一旦不是32为int或者void就返回false

可以看到能够skip的函数都是void返回类型或者Int32的才能处理。能够skip的原因是通过新建一个要么返回0要么返回void的函数来代替。
dump
最后一个dump
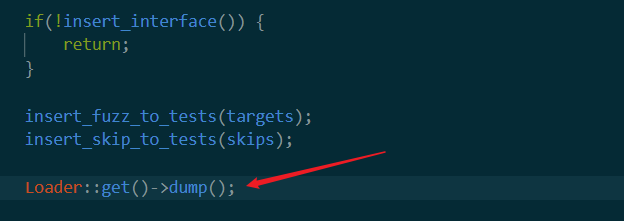
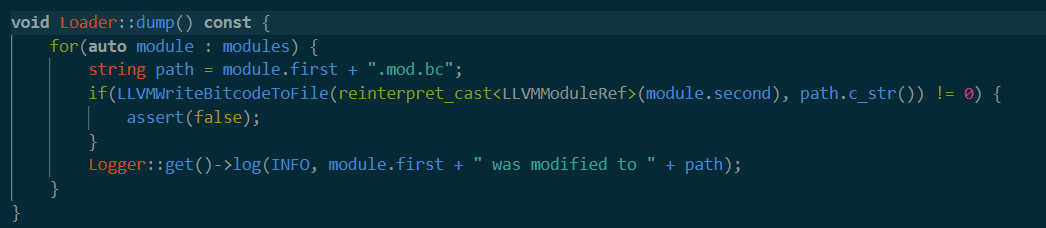
就是把上面所做的修改放回到.mod.bc文件中
芜湖!终于分析完了一半!
exec的总结
finish on April4.5 13:49
总结一下看了将近15小时的exec部分!大概就是根据要fuzz的函数,先从目标文件中找到所有调用目标函数的,再从中去掉skip的函数。之后硬改调用目标函数的语句,把buffer和长度都改为一个全局变量(这个是我没看懂的部分,后面再尝试理解)去掉assert函数以及把所有返回值为void或者int32的能skip的函数全部patch为空,返回void以及0。然后把这个文件dump出来。
最后可以看一下用户指定的文件的真实面目如何。其实正是包含了刚才所说的大部分变量内容(target是目标muzz函数,包括了buffer位置和长度,tests是一个函数名前缀,表示test_开头的全部函数都需要被找到,files表示要找的.bc文件,skips表示需要跳过的函数)。
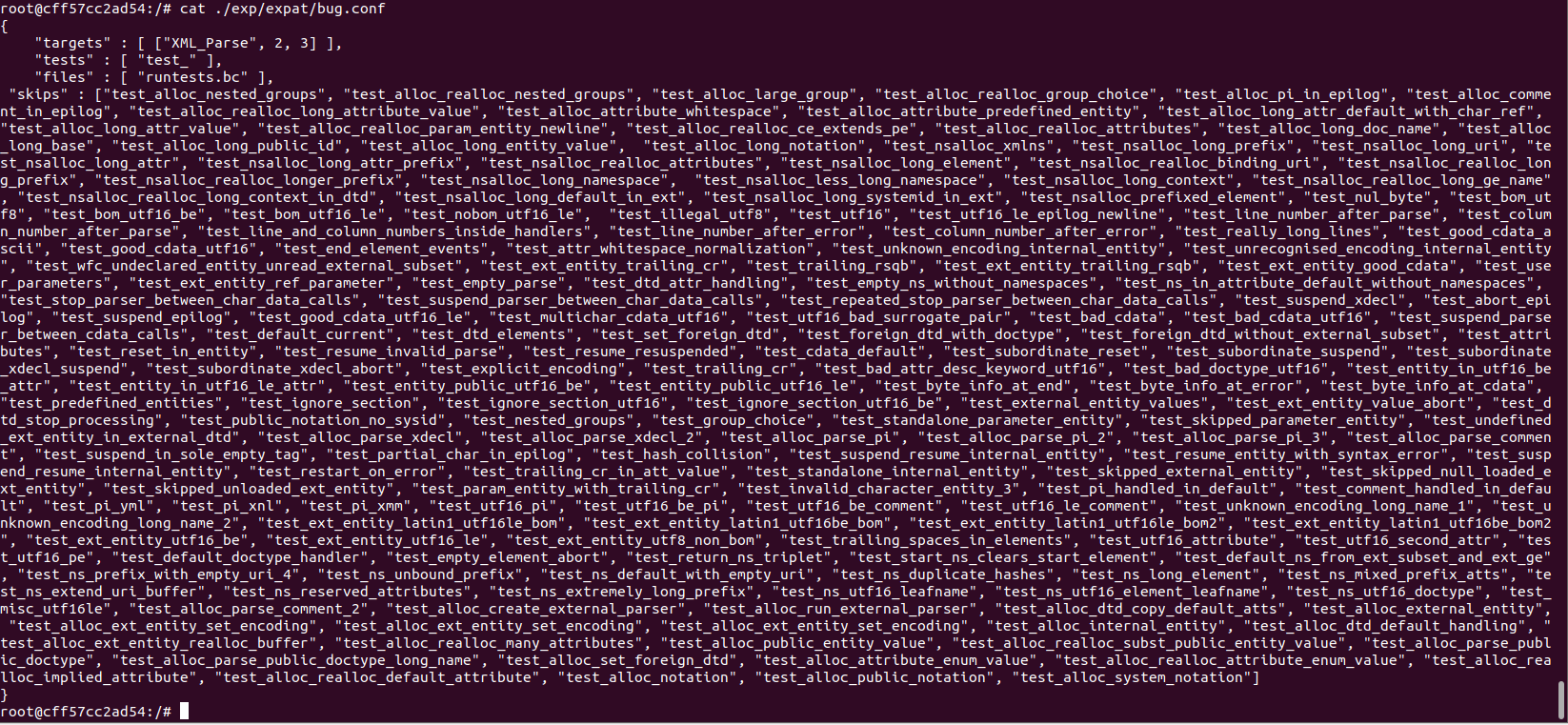
seed部分
首先看看seed是什么。seed就是一种样例输入。在灰盒测试里面seed能带来更高的代码覆盖率。这里的seed部分关注如何自动生成一些有用的seed。

seed部分主要在seedgen.cc里面。seed部分主要调用generate函数来生成seed。有以下函数需要关注。
get_target_functions
获取目标函数。

这里比较的f和target分别是什么呢? f是我们新加载进来的模块。而target,就是我们在上面花了很久找到的寻找target函数的逻辑。可以看到上面的逻辑是在target中逐个找module里面的函数,如果找到了就放到数组中。(为什么要找?大概是为了看新的文件里面有哪些是我们要fuzz的?)

后面两句就是输出target func。然后到最关键的最后一步:insert_collect_to_targets()
insert_collect_to_targets

这里传入的参数就是target。这是一个很可怕的函数。。。
writer.collect()
注意到下面所操作的f都是初始化的时候带入的f。
1 | void IRWriter::collect() { |
用到很多次的create_call。参数为函数类型,自己调用的函数,参数列表,twine是一种用字符串表示的临时变量。最后一个mdnode实在没看明白。
运行结果
以下是运行了seed之后的结果。