学习手动实现编译器上面的编译器原理内容,希望难度不大,能跟着学下去~
crafting-interpreters 1
镇楼
My hope is that if you’ve felt intimidated by languages and this book helps you overcome that fear, maybe I’ll leave you just a tiny bit braver than you were before.
镇楼*2,编译的流程图
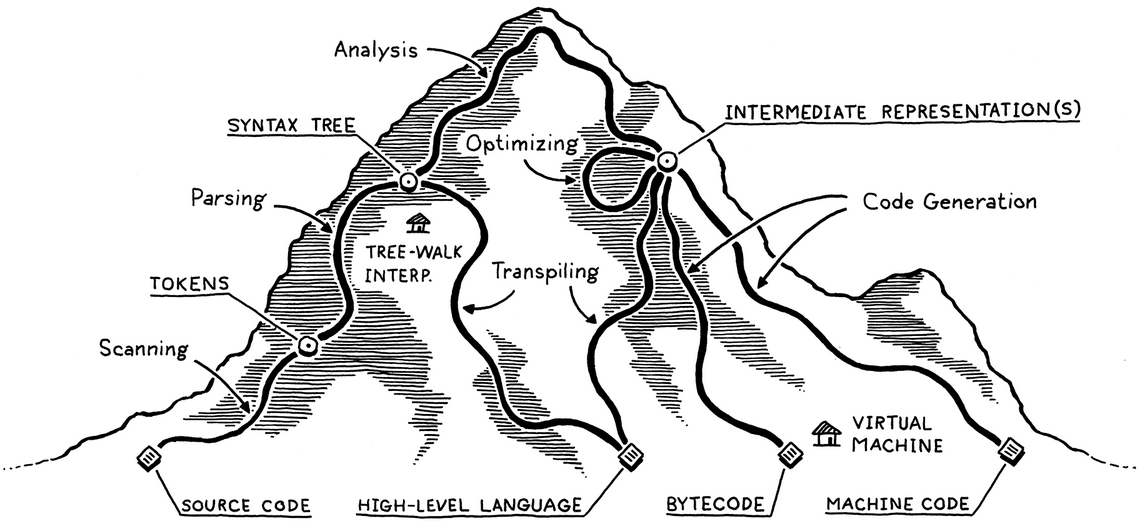
map of territory
我们可以从上面这张图入手,分析一下一个编译器看到一段代码之后会发生什么事情
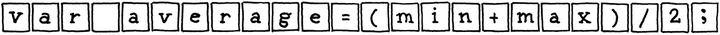
step1: scanning
第一步是扫描,也叫做词法分析。一个扫描器接受一系列线性流(也就是刚才提到的词语的组合),并把他们组合在一起,生成一系列更接近词的东西(也叫做word/token)。有些token是单个的字符,比如括号,或者是逗号。另外一些可以是字符串,(“hi”),或者类似min这类的区分符号。
在这一步中,编译器会去掉类似空格,或者注释等。这种情况下,上面这句话最终将变成这种形式。

step2: parse
这一部分编译器需要把长的表达式分成更小的部分,比桑说:生成AST。
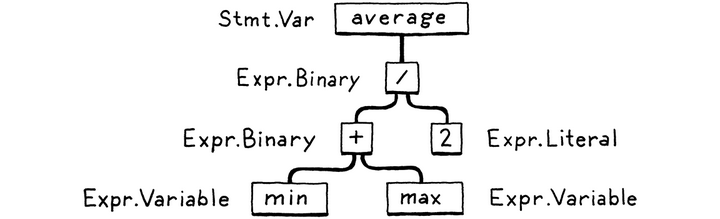
这里就将average的表达式拆分成上面的表达形式。
step3:static analysis
在上面两步中,几乎是所有语言都会进行的操作,接下来的内容对于不同语言,就会产生不同实现。
一个很简单的例子:比方说对于提到的变量a和b我们怎么追溯到他的值,也不知道他的属性(比方说:是否是全局的,是静态还是局部等),也就是binding/resolution
当我们在检查变量在哪里定义的时候,scope的作用就在于此被发挥,scope决定了在某个时刻,一个变量是否能被引用。
接着我们还检查变量的类型。如果变量a和变量b不支持加法操作,那么我们会抛出一个type error。
我们这些分析的内容,需要被保存下来。有一些方法
- 保存在参数树上
- 保存在一个符号表中,用变量的名称指代变量
- 将树转换为全新的数据结构从而更好地体现代码的语义。
总结
上面三点称作编译器前端的工作。也很好理解。前端代表我们如何处理用户输入,解析用户的语句表达式,而后端则更注重怎样将代码转化为机器语言。接下来介绍的中间语言就是两者之间的桥梁。
IR
在前端和后端之间的中间语言(IR)承担的工作是在两种语言之间搭建桥梁。也就是说:我们可以依赖中间表示,从而并不在意我们编写的代码最终运行在哪种架构的机器上。类似gcc使用的中间语言就是GIMPLE。
optimization
编译器除了翻译文件之外,还要做的很重要的事情就是优化。一个常见的例子就是常量折叠。如果我们要反复计算某个数值,我们可以单独把结果作为计算表达式的代替。例如作者给出的例子。将下面这一行,直接用结果代替。


常见的优化措施例如:循环展开,死代码消除,全局变量计数等。
code generate
在完成了上述步骤之后,最后一步就是要生成真正能够运行的机器代码。也就是01二进制机器码。但是这里要牵涉到对于特种架构的代码生成。我们也要在这里考虑究竟是针对虚拟机生成还是针对真实机器生成。
虚拟机
一般来说字节码(bytecode)翻译成机器码(native code或者machine code)也是需要一次转换。这里一般的思路就是把字节码当作中间表示,再转化为CPU所能识别的。但是在这一过程中,我们最好能够根据不同架构进行分别处理和优化。
我们的另一种思路就是生成一个虚拟机。这种情况下我们的代码将可以在任何平台上面运行。但是速度将会稍慢。但是如果我们用c这种语言来编写虚拟机,速度也不会影响很大。
runtime
runtime中,可以包含一些代码运行时的常见问题补救。比方说java的runtime就存在垃圾回收机制,用来辅助运行时能够更加安全等。
shortcuts
上面的整个流程,往往很多语言不会全部都加到自己的特性中,而是挑选其中的一部分。以下是一些案例。
single pass compiler
此类编译器并不处理符号,而是直接根据语法树的特性把文件编译成字节码。参数直接翻译技术使得我们直接将一部分特定的语法和动作联系起来。只要我们看到一些表达式时,就能够直接将其编译。
C语言和Pascal语言就具有这一类特性。
tree walk interpreter
有一部分原因呢可以直接在AST的基础上执行。这类语言直接采用遍历树的方法获取结果。一般来说这种编译器比较简单。在YARV虚拟机上工作的Ruby1.9就是用这种方式运行的。
transpilers
这种编译器很好笑,他把一种高级语言A转化为另一种高级语言B,然后用高级语言B的编译器来执行。这类编译器又被称作source-to-source compiler。例如有很多的语言都会把自身转化为javascript。因为javascript在过去是唯一一种可以在浏览器上执行的代码。现在还有web assembly。
另外还有一些transpilers可以把8080汇编转化为8086汇编。
JIT编译
动态生成代码技术(just in time)可以确保用户load代码时,能够直接根据电脑所在的硬件平台生成机器码。
compiler v.s interpreter
编译器(compiler)和解释器(interpreter)的区别是什么呢?
编译:把一种源代码转化为另外一种通常来说是低级的表示形式。
解释:表示我们接受源码并且直接执行它。也就是“从源码直接执行文件”
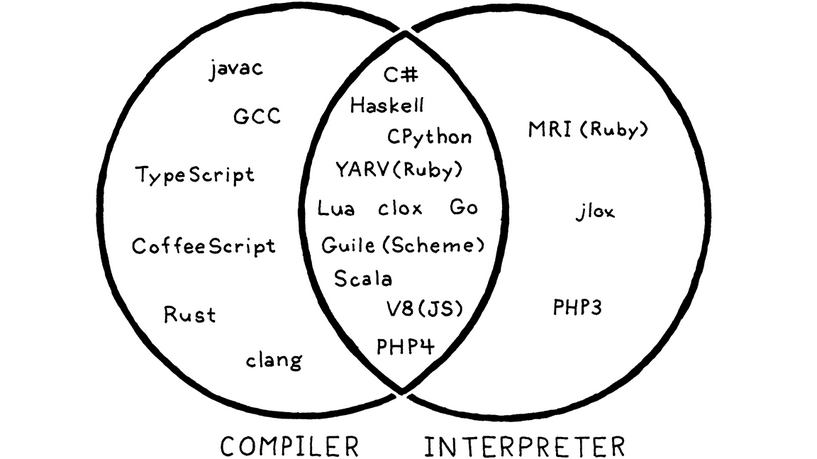
比方说一个例子:go语言,go语言是一个编译器(我们可以编译go语言,并且不执行它),也是一个解释器(我们可以直接从源码运行go语言)。而解释的过程,也是需要编译的,只不过是在内部发生的。
比较纯正的编译器比方说gcc,javac等,就只能编译,但是不能执行。
JIT的缺陷
文章末尾提示一个问题:思考JIT技术的弊端。
JIT技术显然可以很好的优化代码。在网上查到JIT技术可以减少缺页发生的频率,从而加快代码编译之后的执行速度。
但是弊端是:JIT技术依赖动态生成源码,也就是我们打开并运行程序需要的时间可能比较久。此外也比较消耗内存,因为需要实时编译。