关于fuzz领域看的第二篇论文。这篇论文创新性的将数据流差距和控制流顺序也放在seed评估中(而不是传统的代码覆盖率),并自动化的实现了从core dump和patchlog中提取数据限制的方法。提升了对于direct fuzz效率的提升。
Constraint-guided Directed Greybox Fuzzing
一、概述
作者在现在有的DGF的前提下,新增了代码流顺序以及数据流作为seed优劣的一个选择标志。对于堆栈溢出以及UAF等对于代码执行顺序有要求以及对数据要求较高的漏洞提供了一个较好的复现基础。
此外,作者通过自动化分析core dump和patchlog可以直接得到上述的constrains用于fuzz,大大提升了人工分析时间。
二、论文背景及前提
所解决的问题
当前的direct greybox fuzzing在达到目标位置时的速度较慢,因为没有考虑到达到目标位置的控制流顺序和数据要求(data condition)本文通过自动识别并使得fuzz通过一系列的限制(该限制也是自动生成的)到达目标代码区域,用来增大fuzz效率。
解决问题的前提
一般来说,grey box fuzzing在给定一些条件,比如开发者们获取了一个第三方用户的crash report之后,复现起来相对于通过代码覆盖率guided的fuzzing方式还是比较容易的。传统的DGF并没有考虑到数据流的依赖(例如栈溢出,POC生成),也进行了关于目标位置之间相互独立的错误假设(例如UAF)。
三、技术原理与实现
CGDF评估方式
文章开发了一种以限制为导向的grey box fuzzing工具,CGDF。CGDF的目标是通过满足一系列的限制来达到最终target site。其中目标分为数据流和控制流两方面。
判断某个seed是否足够满足constrains的方法,CGDF设计了一种distance of the constrains。和传统的DGF不同。下图中红色框是free(),蓝色框是UAF的位置。
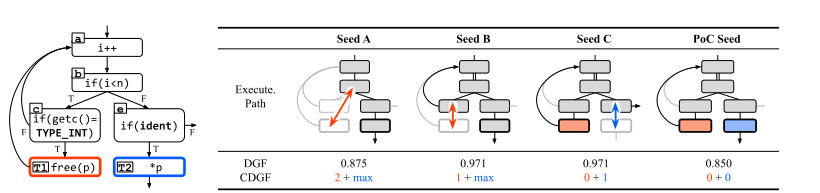
例如使用seedA,使用DGF计算距离时首先第一个块距离两个块距离都是3,因此使用调和平均,(1/3+1/3)^(-1)得到3/2。而如果两者不同,则选择到达目标块的最近距离,例如计算e块,e到达红色快距离是3,到达蓝色快是1,因此就计算为1,那么在e块的结果就是(1/1)^(-1)=1.以此类推。因此总的来说,使用DGF得到的距离之和是
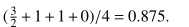
这样计算的好处是,如果seed能够cover更多的标准块,那么确实这个距离总和会变少。
但是我们注意到对于UAF,虽然seedA的DGF距离计算最小,但是它其实并不是理想的UAF触发行为。相反,C才是。然而C的得分却并不高。这正是DGF的independent site所导致的。
另外一个例子是和数据流有关。如果我们需要访问buf的末尾,这里使用DGF时,由于只需要迭代四次,因此会误认为seedA对应的DGF值最小。但是其实seedC对应的值才是最符合条件的。
为了确保解决上述问题,CGDF定义了新的距离表示方式。当满足以下条件时,CGDF会给出更短的seed距离。
- 这个seed满足了更多的constrains
- 这个seed和首个unsatisfied constraint距离更近。
针对以上计算方式
以UAF作为例子。看seedA,其距离最先要满足的一个constraint距离是2,并且距离第二个条件%use由于data不满足,距离是MAX。因此结论是MAX+2。
再看seedB,距离第一个条件最近的块是c块,距离为1,因此未1+MAX。
再看seedC,第一个条件已经满足,而距离第二个条件距离为1.因此两个加起来就是0+1。这样确实给出了较好的优先级顺序。
以越界读为例子,只考虑数据流,也就是越界读的位置和当前读到的位置之差。seedA总共是40,当前读了10,因此CGDF计算的结果是40-10=30,以此类推。
我们怎么生成constrains?可以直接从core dump中提取。==但是怎么提取网上没有找到好的方法==。

生成constrains
- 变量捕获
一旦我们经过target site,我们会通过变量类型识别一些变量,比方说设置&buf[]为addr,设置L*10为size等。
- 数据条件
是一个boolean表达式,例如alloc.size<=access.addr-alloc.ret这个判断条件。
- 顺序
如果有多个条件需要同时满足,需要对constrains作出一些条件限制。
constrains的距离
- basic block distance
对于两个基本块之间的距离可以表示为
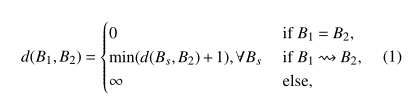
其中Bs是B1的后继,其实也就是类似路由算法的一个方程(名字忘记了),也就是非常直观的计算基本块之间的距离。
- target site distance
和之前basic block distance基本一致
- data condition distance
下面这张图比较明显。其实就是我们定义了一些数据之间的差距。
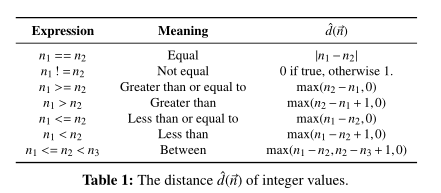
规则为:对于基本块之间的数据差距。是识别到的所有变量之间的差距之和(但是注意这里的comparison operator需要是一样的)。如果有没有识别到的,那就是无穷大。
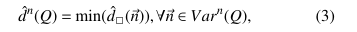
对于使用assert标记的数据条件,我们使用pass或者fail表示。
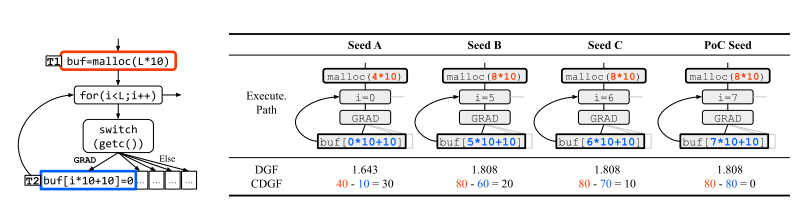
对于多个数据条件的情况,使用如下公式
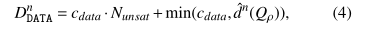
理解:$N_{unsat}$代表所有不满足data condition的条件数量,cdata是一个4byte的数字。并且后面加上了最小的距离值,这样是突出了最近距离的数据的重要性。
constrains距离总和
简单来说,综合控制流和数据流的距离,我们把两者的和作为结果。具体来说,在到达target site之前,距离是
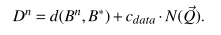
也就是基本块之间的距离+数据流之间的距离。但是此时数据流之间的距离是最大的数据条件距离和所有需要满足的数据条件的数量之和。(也就是一个非常大的值,用最大的距离乘上最多的标准快)
当到达target site之后,距离变为下图。此时只需要考虑数据流距离。
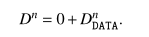
到最后,变为0就可以了。
但是注意constrains距离只是其中一个控制流线之下的距离总和。如果我们考虑多个控制流下的总距离,需要用以下公式。
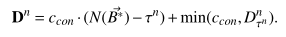
对于三种情况讨论
- 当没有限制满足时
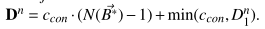
此时$\tau$是1,这里的1很有意思,从数据流看出应该是所有需要满足的条件中最近的一个。
- 当所有控制流条件满足,并且数据流未满足时,前半部分控制流的$\tau$就是N(B*)因此前半部分没有了,只是计算数据流满足
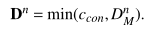
生成constrains
之前提到的生成约束图的方式,在这里是细节。
对于使用core dump生成constraint的方式,使用模板nT(UAF,double free),或者2T+D(两个target site和一个data,例如heap overflow),或者1T+D,例如assertion failure或者除0。如下所示

这里的2T+D的生成方式中的assert的目的是确保access到的地址是在之前分配的地址之间。之后我们通过设置cond来驱使产生溢出。

除此以外,生成constrains还有几个原则
- 避免wrapper函数
使得target site更加有标识性。通过检查函数名中是否包含keyword,类似alloc(),free()等
利用patch生成constrains
使用1T+D的模板可以很方便的生成。具体算法如下

有以下集中生成constrais的规则
- 如果引入了新的exception检查,设置
target site到其源地址(我理解是exception所检查的地方)并用新的exception检查条件创建data_cond。在这里将throw或者error识别为exception check。 - 如果任何分支语句被修改了,设置
target_site到被改掉的条件的地方,并根据patch之前和之后互斥的数据条件修改data_cond。也就是下面的公式。个人认为这样设置因为要找到不属于两个条件之间的情况,进行fuzz。
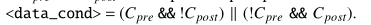
- 如果有变量被修改,设置
target site到被修改的变量,创建data_cond并检验修改之前和之后的变量数值是否相同。 - 如果上述条件都不满足,则对新增的代码设置为target_site进行修改。
CAFL实现
CAFL首先生成LLVM的IR代码,并用AFL编译器来instrument。之后生成call graph以及instrument target site(在编译时加上一些标记checkpoint,指示目前的位置),并捕获变量,将其转发到CAFL runtime。
CAFL runtime
CAFL runtime从checkpoint接受目标位置的距离[$\tau$,d($B^{n}$,$B_{\tau}$)]其中$\tau$是限制的下标。d是basic block之间的距离。在target site位置,CAFL runtime接受从checkpoint捕获到的变量,计算data之间的距离(在这里还考虑到放置由于内存回收造成地址偏移发生改变)
CAFL fuzzer
对于seed选择的策略:
- seed 评分
按照总长度较短的seed给与更高的分数,同时避免局部最优(没有给出具体方法)
- seed 创建
也没有给出具体算法。当一个中子覆盖了更多边时,就生成一个新的seed(?)
- seed 最优化选择
按照seed排名的指数倒数作为当前seed被选中的概率来选择seed。
四、实验评估
实验数据结果
以下是从LAVA1中获取到的制造crash的时间对比。
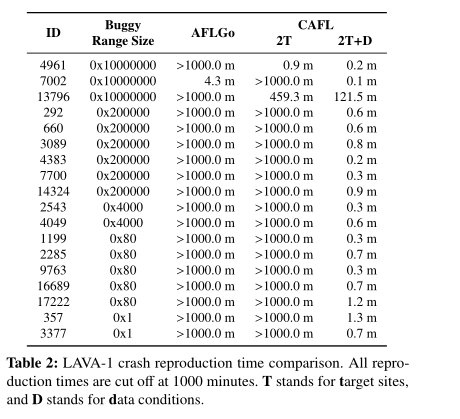
以上将CAFL和AFLGo做对比,发现新增data condition的CAFL到达目标地址的时间确实短了许多。
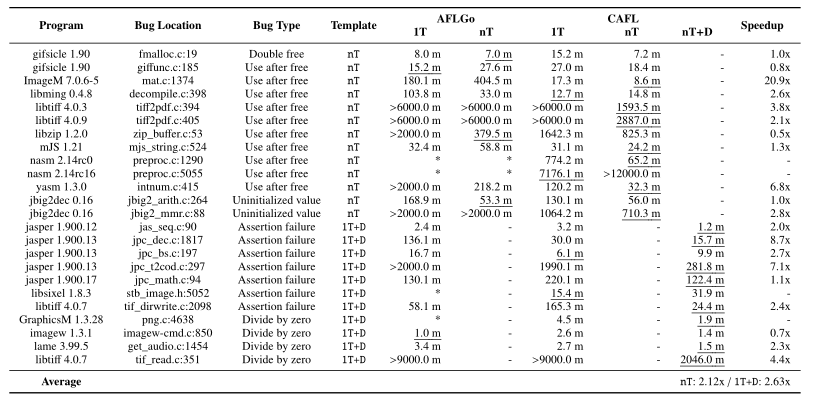
接下来,寻找crash reproduction时间对比。使用了ASAN和MS。这里比较alpha GO和CAFL在多种目标下的crash reproduction时间,主要是为了验证数据流存在的意义
PoC生成
最后一个是PoC生成功能。使用git和Mercurial可以自动生成constrains
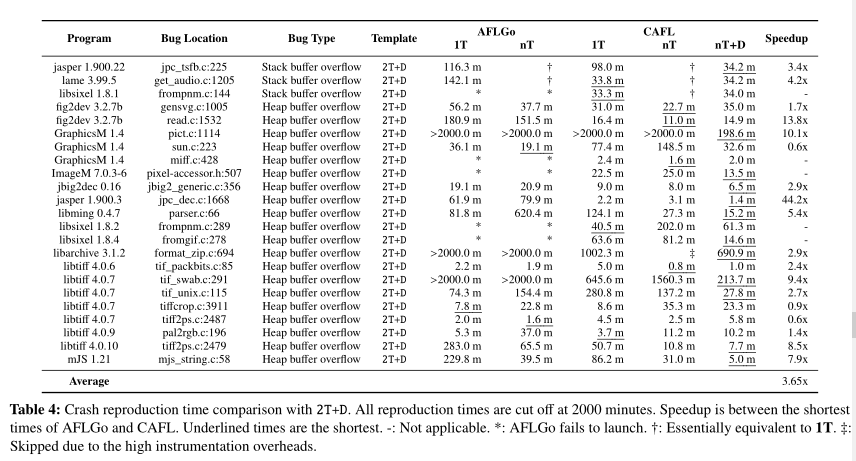
上面主要是堆溢出漏洞,使用CAFL的nT+D可以显著加快速度。
另外对于1T下的数据流对比。

现有问题
- 论文结尾提到对于栈溢出漏洞可能需要grammar fuzzing进行补充,目前CAFL无法做到。
- 对于例如数据未初始化漏洞等和控制流角度关系较小的漏洞,目前CAFL还无法处理。
- 对于例如全局缓冲区溢出和buffer负数溢出的bug,