最近几天做了一个提取微信聊天,做成词云的工具,记录在这里,防止忘记~
step1 提取微信聊天数据库
这一步最好的方式是通过电脑版微信,备份手机微信,之后再用安卓模拟器重新载入聊天记录,获取聊天记录的db文件。
电脑板微信点击下面,迁移与备份

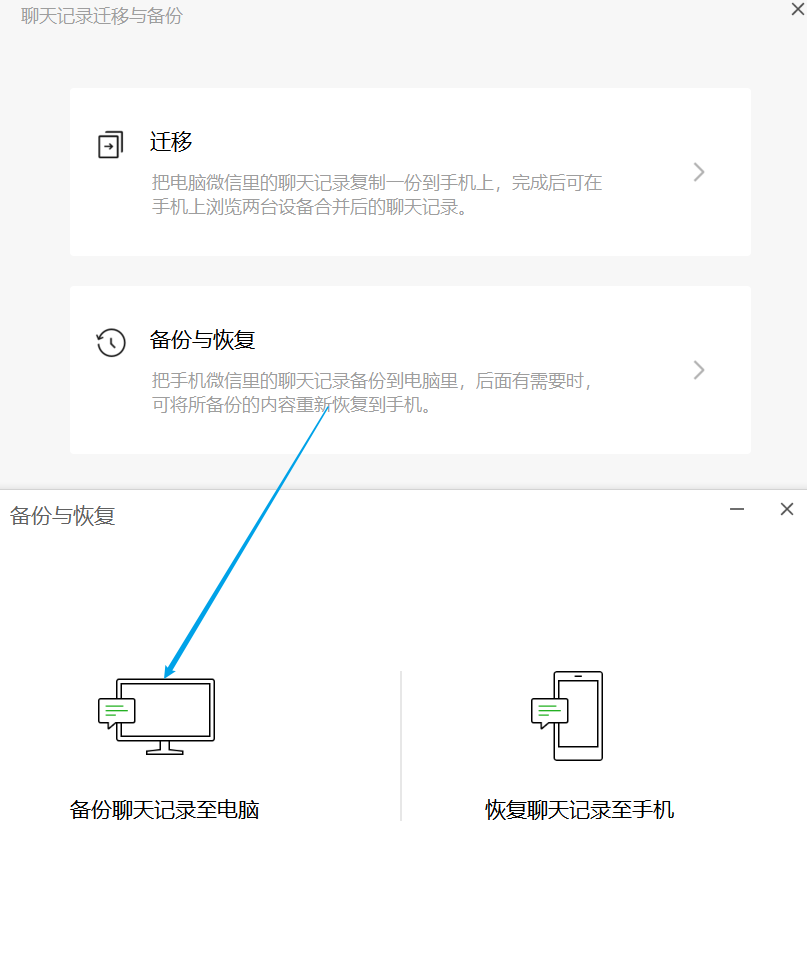
这里要注意!如果出现”网络情况复杂,请稍后再试“,无论是不是用同一网络都不行!
此时需要进入网络设置,禁用VMWARE的虚拟网卡。
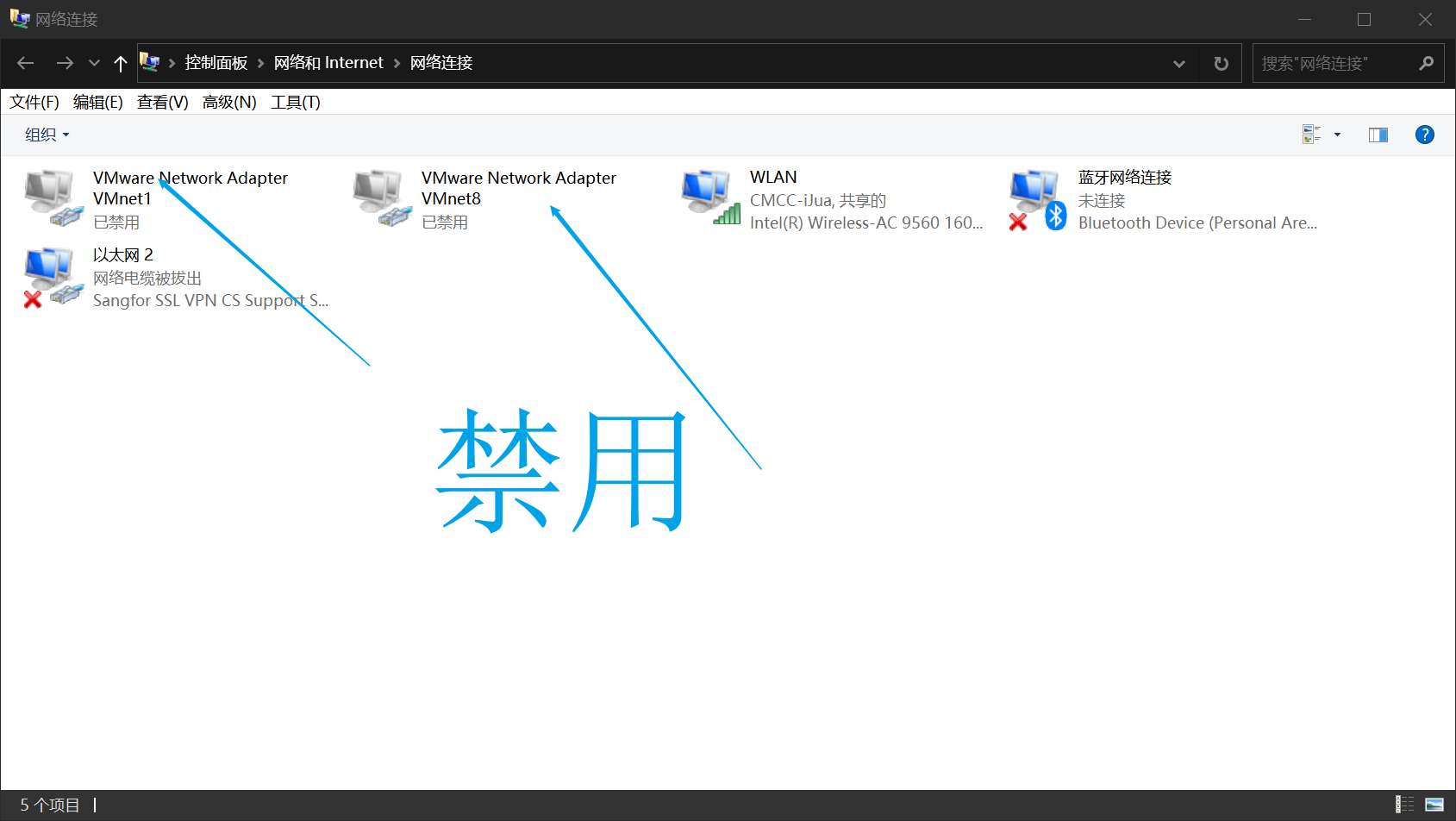
之后在手机上面,选择想要生成词云的人的消息记录,导出到电脑即可。注意这里比较坑,一旦模拟器登录,电脑就会登出,而电脑登陆又要手机扫码。。解决办法是在模拟器里扫码,直接用模拟器的扫一扫,把微信的二维码扫一下就可以了。
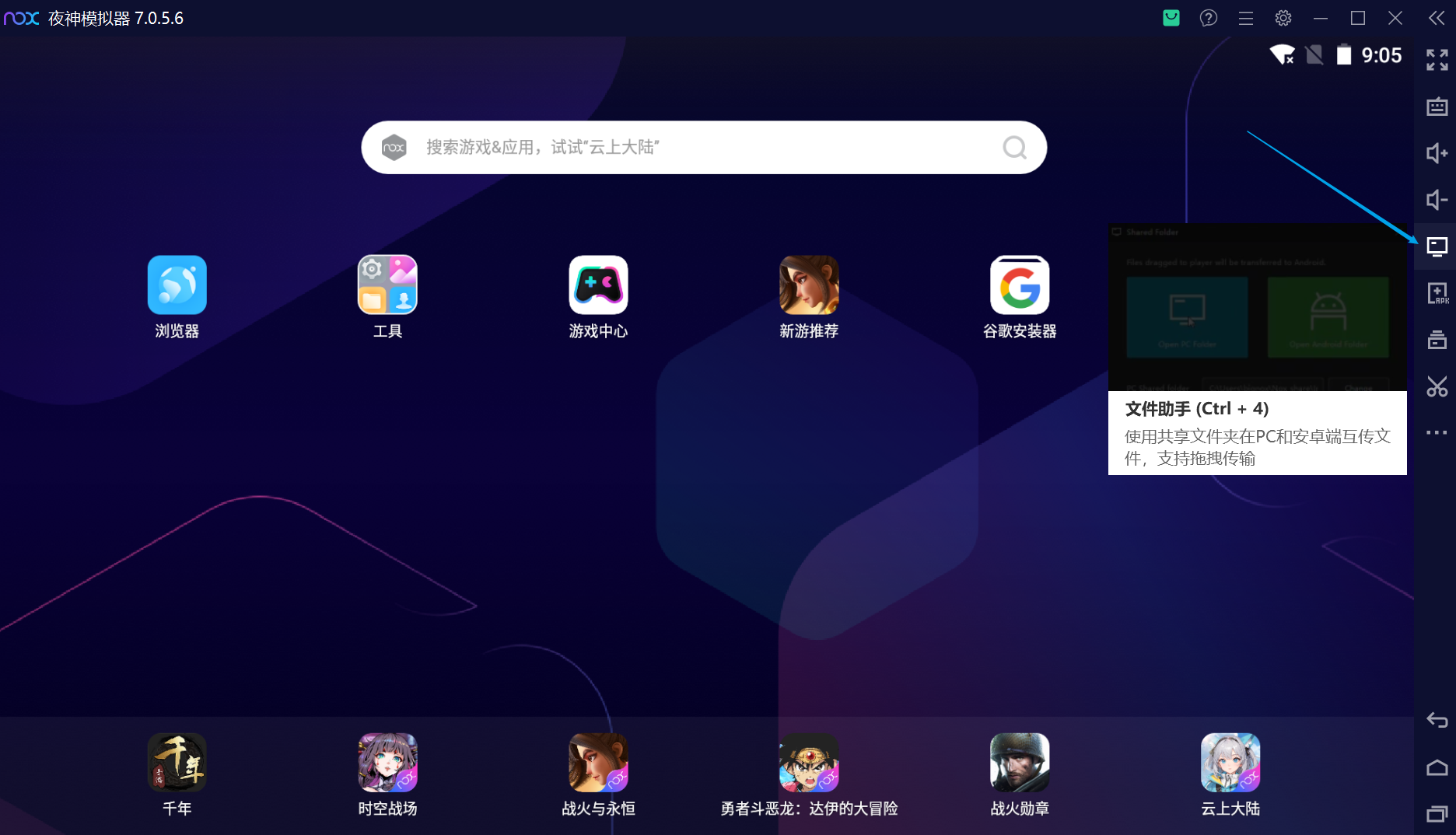
之后下载安卓模拟器。我在夜神模拟器7.0.5.6测试可以成功。在夜神模拟器中导入此聊天记录(漫长的等待)
导入之后,需要在root模式下,进入文件管理器,找到对应数据库文件。这里的路径是**/data/data/com.tencent.mm/MicroMsg**。注意不需要下载什么文件管理器,直接用夜神模拟器自带的文件管理系统就可以了。
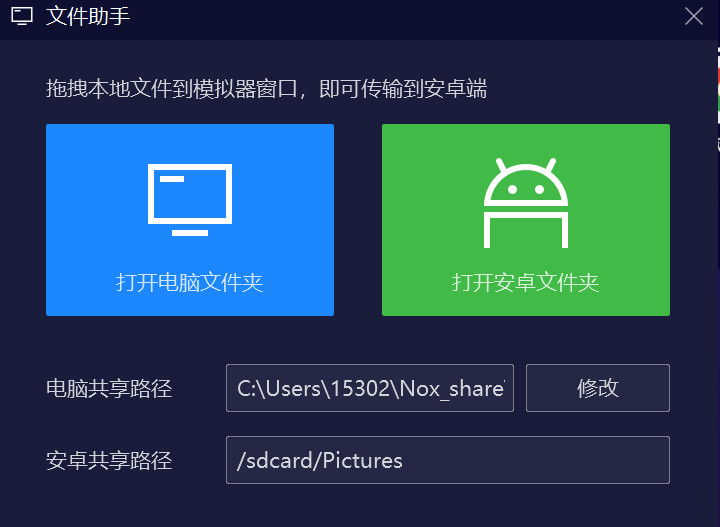
点了这个文件助手之后,需要设置一个电脑共享路径。这样就可以在模拟器和主机之间,直接通过文件系统传递文件。
之后找到上述路径。看到这里有一个很长的文件夹名字。(如果有多个,选择最近修改的那个)点进去。这里就是5014…的文件夹
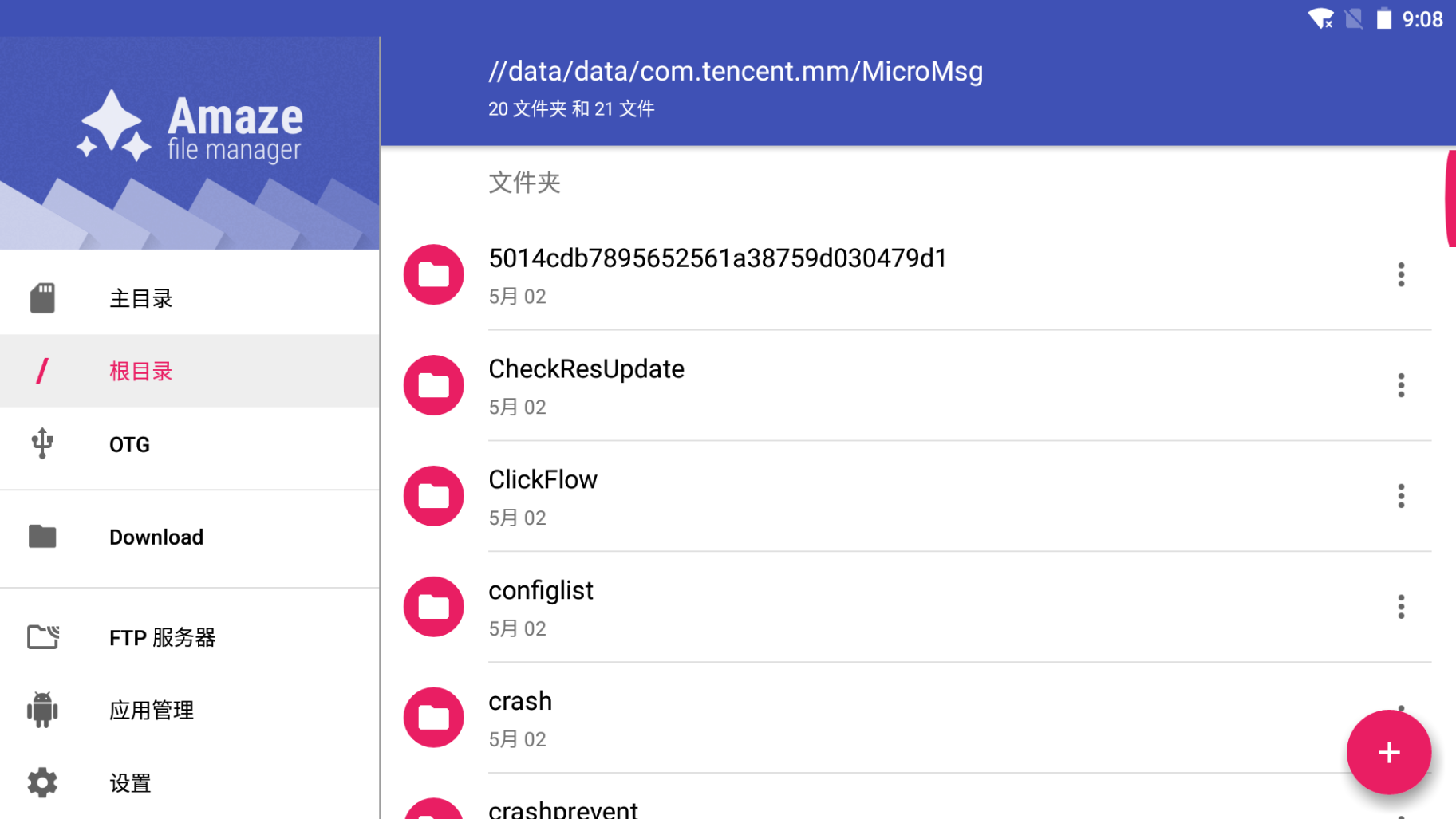
找到其中的EnMicroMsg.db。将他复制出来。方法就是点击文件最右边的三个点,选择复制,粘贴到和电脑的共享路径就可以了。
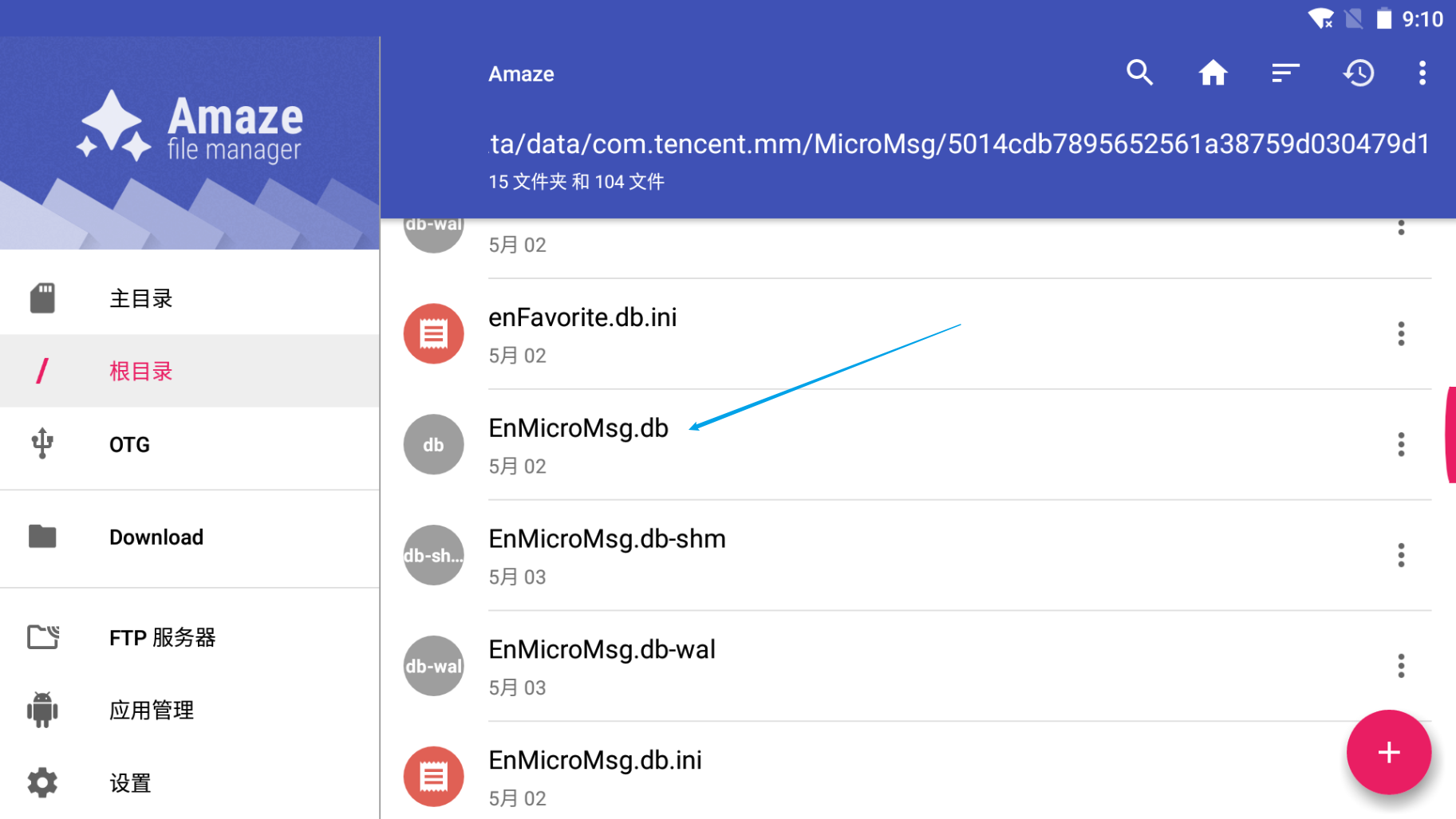
导出之后需要安装一个sqlcipher.exe。这个原版的网上找不到了,大家也可以自己下载开源的,这里我直接放一个exe文件,大家放心的话可以直接下载来用
step2解密数据库密码
将之前导出的db文件放入sqlcipher.exe,发现文件是加密的。需要输入密码。网上对于这个密码有很多说法,什么uid,什么默认密码。但是现在都不一定对。一个比较推荐的方法是通过fridahook,提取出密码。
首先需要在模拟器和电脑上安装frida。模拟器上安装需要首先安装adb。安装frida可以参考这篇文章。注意要在模拟器里面下载的是server。并且如果是模拟器,要下载x86架构的。之后在电脑上安装python的frida环境。在一切准备就绪之后,可以用下面的脚本hook微信数据库解密db时用到的密码。可以参考此链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import frida
import sys
jscode = """
Java.perform(function(){
var utils = Java.use("com.tencent.wcdb.database.SQLiteDatabase"); // 类的加载路径
utils.openDatabase.overload('java.lang.String', '[B', 'com.tencent.wcdb.database.SQLiteCipherSpec', 'com.tencent.wcdb.database.SQLiteDatabase$CursorFactory', 'int', 'com.tencent.wcdb.DatabaseErrorHandler', 'int').implementation = function(a,b,c,d,e,f,g){
console.log("Hook start......");
var JavaString = Java.use("java.lang.String");
var database = this.openDatabase(a,b,c,d,e,f,g);
send(a);
console.log(JavaString.$new(b));
send("Hook ending......");
return database;
};
});
"""
def on_message(message,data):
if message["type"] == "send":
print("[*] {0}".format(message["payload"]))
else:
print(message)
process = frida.get_remote_device()
pid = process.spawn(['com.tencent.mm'])
session = process.attach(pid)
script = session.create_script(jscode)
script.on('message',on_message)
script.load()
process.resume(pid)
sys.stdin.read()
|
运行之后即获得数据库解密密码。如果到时候API变了,也可以用类似的方法hook一遍。
step3生成词云
在打开db之后,需要找到message这个数据库(没有什么好办法,一行一行找的)选中,导出成csv文件
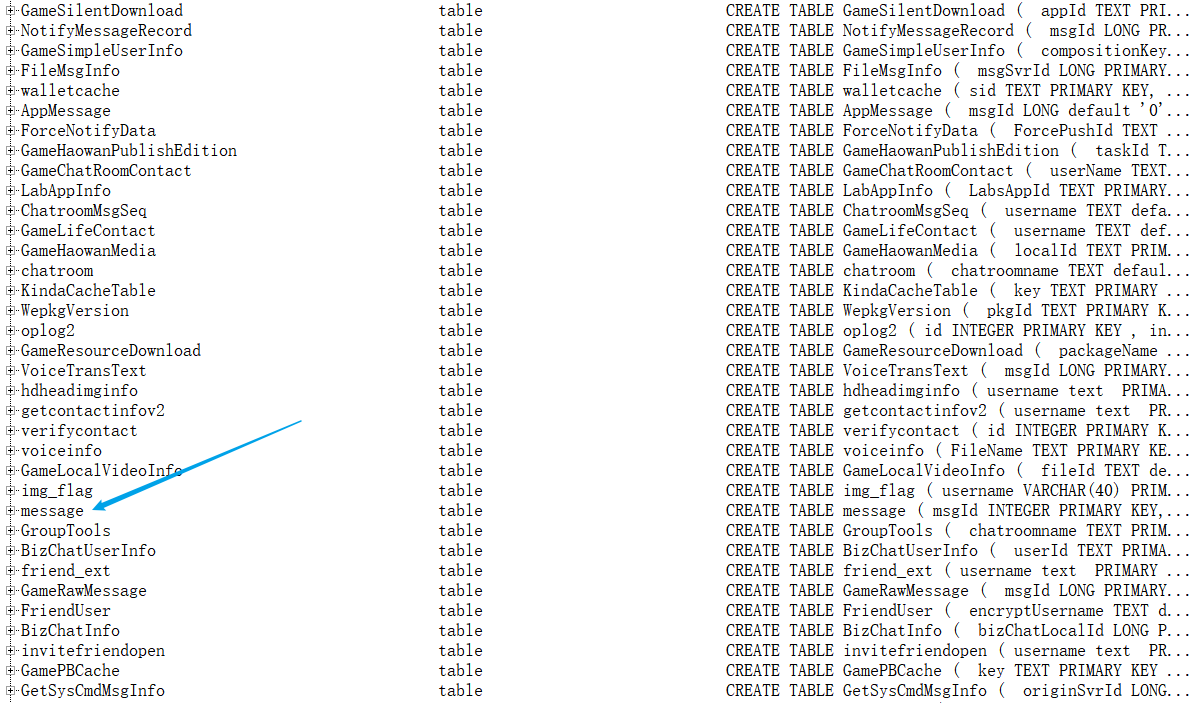
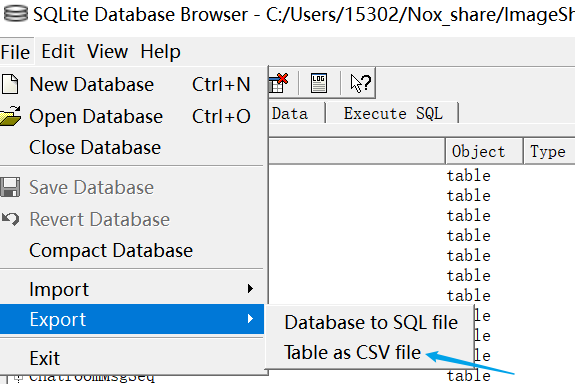
之后就有一个excel文件,找到里面的content,就对应了发的消息的内容~

把这些全部复制出来就可以啦。接下来要生成词云
3.1过滤
过滤消息中的乱码之类的。我通过以下脚本实现。其中message.txt是原本的消息,fliter_msg.txt是过滤之后的消息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| fin = open("message.txt","r",encoding='utf-8')
fout = open("fliter_msg.txt","w",encoding="utf-8")
cnt = 0
stop = ["<",">","https://","wxid",";","\"","撤回","&"]
while(True):
bad = 0
i = fin.readline()
if(not i):
break
for j in stop:
if(i.find(j)!=-1):
bad = 1
if(not bad):
fout.write(i)
cnt += 1
if(cnt % 100 == 0):
print("now process {}", cnt)
fin.close()
fout.close()
|
3.2 分词
这一步我用了jieba的paddle模式。可能会比直接用jieba更好一些? 安装过程如下
1
2
3
4
5
6
| pip install jieba
# 旧版本升级
pip install jieba --upgrade
# 使用paddle模式:结巴版本大于0.4且安装paddlepaddle-tiny模块
pip install paddlepaddle-tiny==1.6.1
|
脚本如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import jieba
import jieba.posseg as pseg
fin = open("fliter_msg.txt","r",encoding="utf-8")
fout_noun = open("fliter_msg_noun.txt","w",encoding="utf-8")
fout_adj = open("fliter_msg_adj.txt","w",encoding="utf-8")
content = fin.read()
jieba.enable_paddle()
words = pseg.cut(content,use_paddle=True)
print('paddle模式')
cnt = 0
for word, flag in words:
cnt +=1
if(flag == "n" or flag == "nr" or flag == "nz"):
fout_noun.write(word)
fout_noun.write("\n")
if(flag == "a" or flag == "ad"):
fout_adj.write(word)
fout_adj.write("\n")
if(cnt % 100000 == 0):
print("now process {}",cnt)
fin.close()
fout_noun.close()
fout_adj.close()
print('+'*10)
|
之后生成两个文件fliter_msg_noun.txt代表名词,fliter_msg_adj.txt代表形容词。
3.3生成词云
这里可以直接用wordcloud库。代码也很简单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
from wordcloud import WordCloud
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba
with open("fliter_msg.txt",encoding="utf-8") as f:
s = f.read()
text = ' '.join(jieba.cut(s))
img = Image.open("./background/pkq.jpg")
mask = np.array(img)
stopwords = ["我","你","她","的","是","了","在","也","和","就","都","这","好","啊","吧","吗","嘛"]
wc = WordCloud(font_path="./STFangSong.ttf",
mask=mask,
width = img.width,
height = img.height,
background_color='white',
max_words=500,
stopwords=stopwords).generate(str(text))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
|
注意这里的遮罩图片,必须选择蒙版类型的。可以上网搜索,下载比较好康的。之后就保存好啦。效果图如下~做了一点马赛克

其实想想这整个过程,如果要自己做的话,包括了安卓逆向、中文分词、数据可视化等好多步骤,甚至可以作为一种综合练习~hhhh
参考链接
- https://zhuanlan.zhihu.com/p/163666886(但是这里的数据库密码不对,现在测下来只能通过frida hook的方式获取了,一定要装好环境,使用adb等)