//launch.json { // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version":"0.2.0", "configurations":[ { "name":"Python: Current File", "type":"python", "request":"launch", "program":"${file}", "args":["-d","/dataset/_RAXE500-V1.0.12.96_2.0.45.chk.extracted","-o","./out2.txt","--ghidra_script=ref2sink_cmdi","--ghidra_script=ref2sink_bof","-b","httpd","--taint_check"], "console":"integratedTerminal", "justMyCode":true, "env":{"PYTHONPATH":"/home/satc/.virtualenvs/SaTC/lib/python2.7/site-packages/"} } ] }
defcheckConstantStr(addr, argpos=0): # empty string is not considered as constant, for it may be uninitialized global variable returnbool(getStrArg(addr, argpos))
defcheckSafeFormat(addr, offset=0): data = getStrArg(addr, offset) if data isNone: returnFalse
fmtIndex = offset for i inrange(len(data) - 1): if data[i] == '%'and data[i + 1] != '%': fmtIndex += 1 if data[i + 1] == 's': if fmtIndex > 3: returnFalse ifnot checkConstantStr(addr, fmtIndex): returnFalse returnTrue
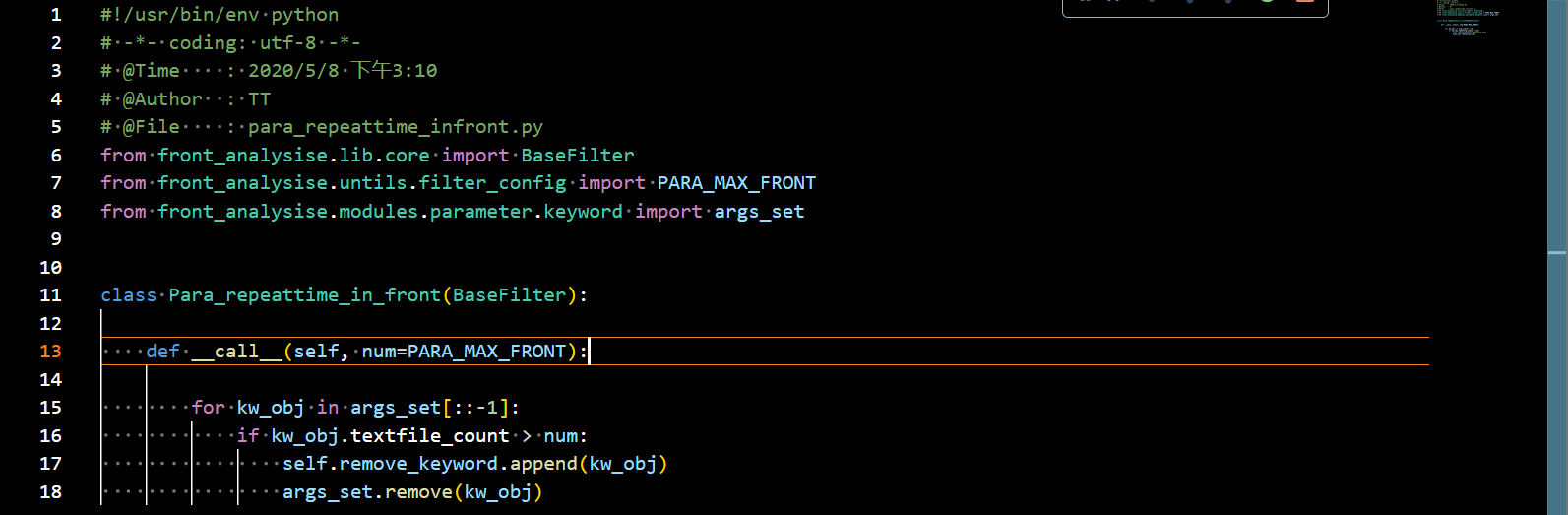
defget_memcpy_like(p): """ Gets and summarizes memcpy like functions within a Linux binary :param p: angr project :return: function summaries """
# TODO: add sprintf summarized_f = {}
addrs = get_dyn_sym_addrs(p, ['sprintf']) for f in addrs: summarized_f[f] = summary_functions.sprintf addrs = get_dyn_sym_addrs(p, ['snprintf']) for f in addrs: summarized_f[f] = summary_functions.snprintf
addrs = get_dyn_sym_addrs(p, ['strcpy','stristr']) print addrs for f in addrs: summarized_f[f] = summary_functions.memcpy_unsized
addrs = get_dyn_sym_addrs(p, ['strncpy', 'memcpy']) for f in addrs: summarized_f[f] = summary_functions.memcpy_sized
if _core.is_tainted(src, path=plt_path_cp) or _core.is_tainted(_core.safe_load(plt_path_cp, src), path=plt_path_cp): # FIXME: make the actual copy so that taint dependency will be respected t = _core.get_sym_val(name=_core.taint_buf, bits=_core.taint_buf_size).reversed else: plt_path_cp.step() assert _core.p.is_hooked(plt_path_cp.active[0].addr), "memcpy_unsized: Summary function relies on angr's " \ "sim procedure, add option use_sim_procedures to the " \ "loader" plt_path.step().step() ifnot plt_path.active: raise Exception("size of function has no active successors, not walking this path...") return dst = getattr(plt_path.active[0].regs, arg_reg_name(p, 0)) plt_path.active[0].memory.store(dst, t)
# restore the register values to return the call _restore_caller_regs(_core, call_site_path, plt_path)
接下来设置sink_addr。这一步在后面coretaint中要用到。
1 2 3 4 5 6 7 8 9 10
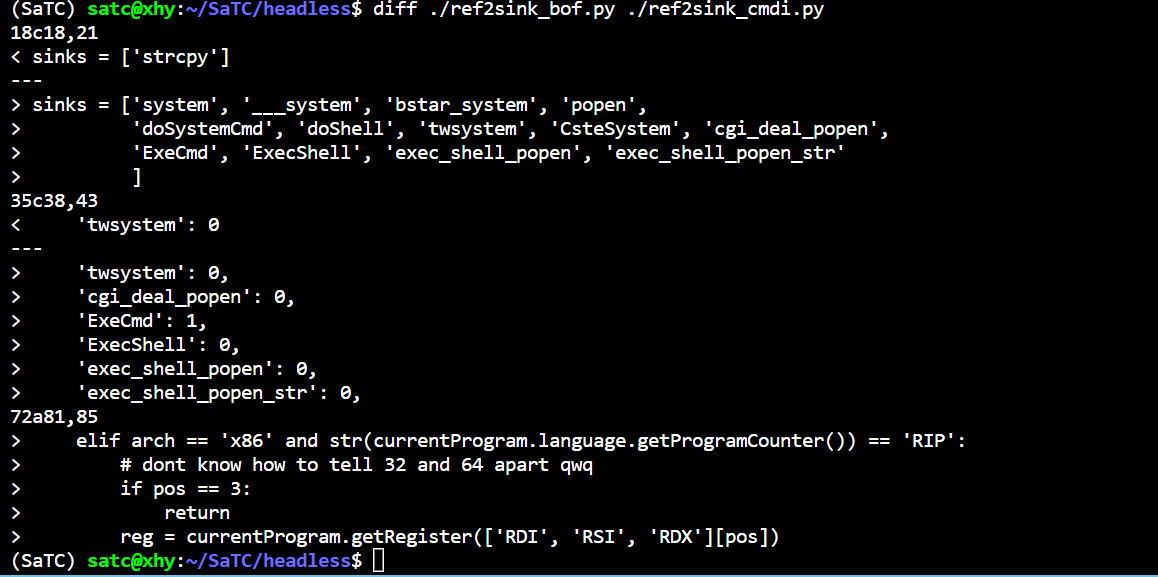
def_find_sink_addresses(self): """ Sets the sink addresses in the current binary's project :return: None """ p = self._current_p # SINK_FUNCS = [('strcpy', sinks.strcpy), ('sprintf', sinks.sprintf), ('fwrite', sinks.fwrite), ('memcpy', sinks.memcpy),('system', sinks.system),('___system', sinks.system),('bstar_system', sinks.system),('popen',sinks.system),('execve',sinks.execve),("doSystemCmd",sinks.doSystemCmd),("twsystem", sinks.system),('CsteSystem', sinks.system)]
self._sink_addrs = [(get_dyn_sym_addr(p, func[0]), func[1]) for func in SINK_FUNCS] self._sink_addrs += [(m, sinks.memcpy) for m in find_memcpy_like(p)]
def_check_sink(self, current_path, guards_info, *_, **__): """ Checks whether the taint propagation analysis lead to a sink, and performs the necessary actions :param current_path: angr current path :param guards_info: guards (ITE) information :return: None """
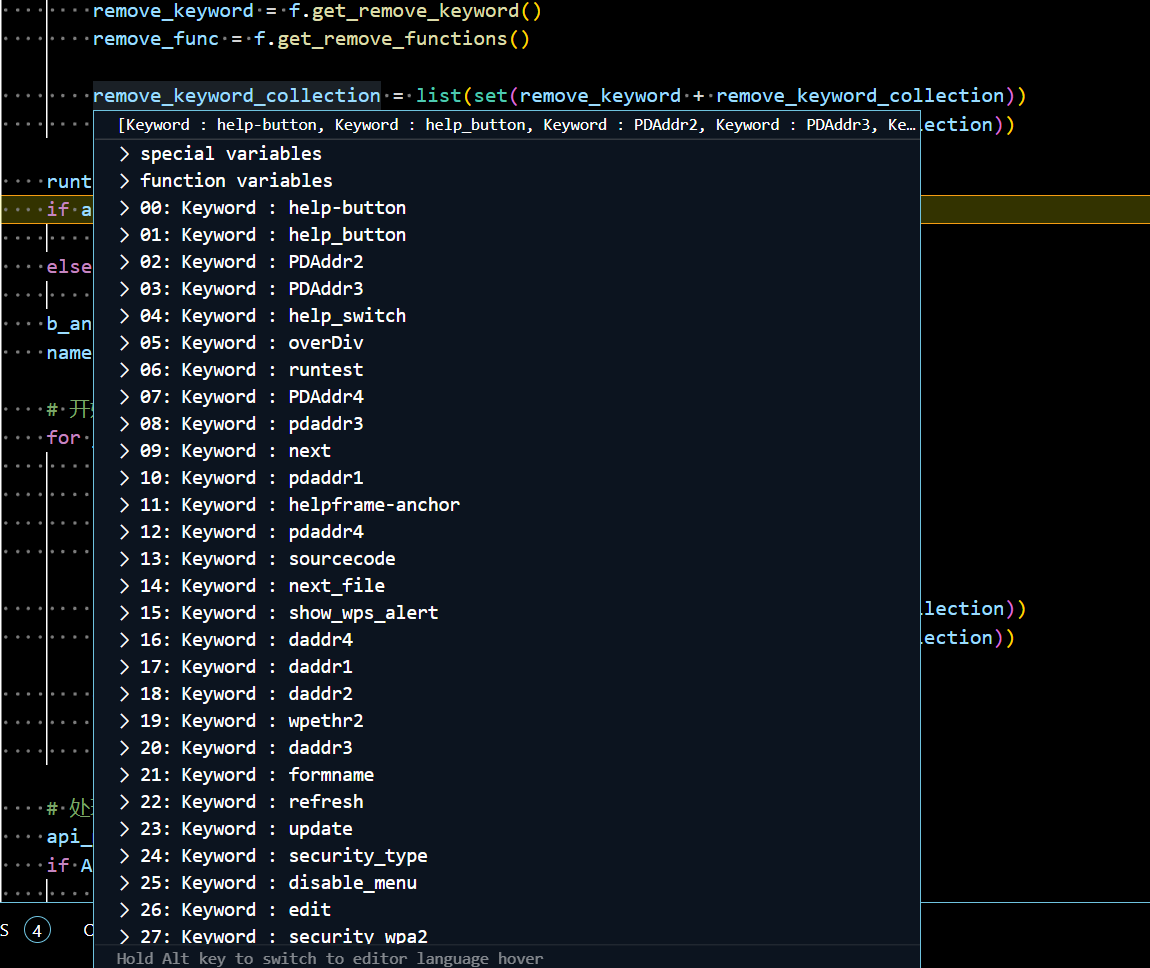
next_state = next_path.unconstrained[0] hash_val = self.bv_to_hash(val_jump_tmp) self._taint_names_applied.append(hash_val) hash_val = self.bv_to_hash(val_jump_reg) self._taint_names_applied.append(hash_val) # 将next_state对应的函数中各个参数taint self._apply_taint(current_addr, current_path, next_state) ### _apply_taint如下所示 def_apply_taint(self, addr, current_path, next_state, taint_key=False): """ Applies the taint to the role function call :param addr: address of the role function :param current_path: current angr's path :param next_state: state at the entry of the function :return: """
defis_arg_key(arg): returnhasattr(arg, 'args') andtype(arg.args[0]) in (int, long) and arg.args[0] == self._current_seed_addr
ifnot are_parameters_in_registers(p): raise Exception("Parameters not in registers: Implement me")
for stmt in ins_args: reg_off = stmt.offset reg_name = p.arch.register_names[reg_off] val_arg = getattr(next_state.regs, reg_name) size = None if is_arg_key(val_arg): ifnot taint_key: continue n_bytes = p.loader.memory.read_bytes(val_arg.args[0], STR_LEN) size = len(get_mem_string(n_bytes)) * 8 if val_arg.concrete and val_arg.args[0] < p.loader.main_object.min_addr: continue log.info('taint applied to %s:%s' % (reg_name, str(val_arg))) self._ct.apply_taint(current_path, val_arg, reg_name, size)
# eventually if we are in a loop guarded by a tainted variable next_active = next_path.active iflen(next_active) > 1: # 大于1说明可能是判断语句,也可能是循环导致 history_addrs = [t for t in current_state.history.bbl_addrs] seen_addr = [a.addr for a in next_active if a.addr in history_addrs] # 寻找当前地址是否出现在history 地址中
iflen(seen_addr) == 0: return
back_jumps = [a for a in seen_addr if a < current_addr] iflen(back_jumps) == 0: return # 所有跳回中选择其中第一个 bj = back_jumps[0] node_s = cfg.get_any_node(bj) node_f = cfg.get_any_node(current_addr)