这几天阅读了一篇关于怎样用AFL对路由器设备进行fuzzing的文章FirmAFL记录一下这篇文章比较有意思的地方。
论文地址:https://www.usenix.org/conference/usenixsecurity19/presentation/zheng
代码仓库:https://github.com/zyw-200/FirmAFL
以往工作的问题
在固件动态分析中,存在一些常见问题,例如
- 对于外设的模拟较难。外设例如天线设备,传感器设备等。大部分iot设备都存在对这类外设的读取,写入,而fuzzing过程中由于无法真正购买这些外设并进行fuzz(也有人试过这么做,论文是IoTFuzzer,结果是Fuzzing效率特别低),因此较难将固件真正运行起来,进行动态测试。目前常见的模拟方式是
firmadyne和firmAE。后者效果应该优于前者。 - 模糊测试中需要大量fork,产生新进程用于同时fuzzing多种payload。但是基于qemu的模拟fork过程中的系统调用开销非常大,也会提升fuzzing的开销。
- 现有的针对iot的模糊测试系统对比如下,目前的code coverage效果都不太理想,而AFL并不能直接用在iot设备上(会出现问题2)

本文提出的augmented process emulation方案解决了上述两个问题。
augmented process emulation
现在常见的基于多种架构的模拟器框架是qemu。作者注意到,qemu中存在两种mode,system mode和user mode。他们分别用于系统层和用户层代码的运行。两者的执行效率也不同,具体而言有如下不同。
- system mode对于每次地址访问的翻译需要经过MMU,内部需要经过GVA(guest virtual address)、HVA(Host Virtual Address)等地址翻译过程。然而user mode中只需要对HVA加上一段偏移即可。这导致user mode中指令执行速度相比system mode快很多
- qemu并不是每碰到一句指令就翻译成host OS的指令,而是以basic block为单位翻译的(因为这个特性,我们可以在翻译过程中对指令进行插桩,从而实现将black box fuzzing转换为grey-box)。在user mode中可以一次性对多个物理页的指令进行翻译,而system mode中一次只能对同一个page的指令翻译。因为多次调用翻译会导致效率降低,所以user mode的指令执行速度将会快于system mode
- user mode的系统调用是直接使用host kernel和硬件进行回应,而system mode则在模拟的硬件和模拟的OS进行回应。后者速度会慢很多
作者发现,由于之前的固件模拟共工作通常使用full-system emulation。导致所有代码都在system-mode下执行,这将导致效率非常地下。因此作者提出一种策略将大部分代码执行限制在HOST OS kernel中,只有当进行系统调用或者缺页中断时才切换到qemu根据固件模拟的kernel。这样可以从两个方面减少运行时开销
- 指令翻译的吞吐量
- 地址访问时page fault处理的速度。
下面时作者的构想图,其中RAMfile是system mode和user mode共享内存的映射表。(当然程序在启动时肯定在full-system mode,只有在到大特定位置,例如开始接受网络数据包之后,才会切换到user mode以加快速度。)
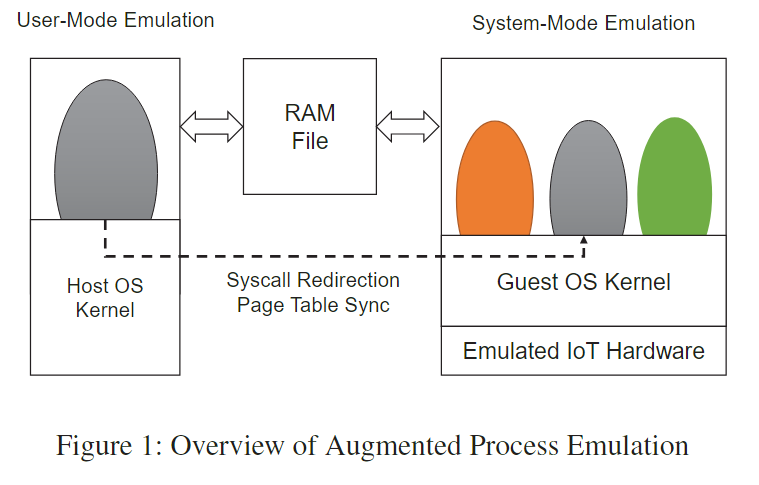
具体做法
怎样具体实现呢?作者因此提出了论文题目中的augmented process emulation模拟策略。实现这个策略有两个先决条件
- 固件可以被一个基于系统的模拟器很好的模拟(基于firmadyne已经可以实现)
- 固件在一个支持多线程的OS上(目前接近50%的路由器是基于Linux架构的)
作者的实验目标是
- 透明性:即模拟在user mode的固件似乎是被模拟在系统层面上
- 高效性:在模拟的user mode程序中,fuzzing的效率应接近用户层的原生程序
然而,会碰到几个问题
- 内存映射。即在user mode中的AFL,无法直接在fork时访问system mode层面的地址空间。这一部分需要修改qemu以配合afl完成fork时的内存映射。
- error page handling:当用户层发生缺页故障时,按照qemu的设计应该被递交给host OS来处理,但是此时需要被模拟的OS来进行处理。需要hook一些地址返回代码来完成这样的请求。解决这一难题的难点时判断何时内核的page mapping已经完成,因为内核在处理缺页时经常是多线程的状态。
- 避免内核的COW机制。在fork的时候,内核经常会为了节省开销而使用copy on write机制。如果在fuzzing过程中使用COW,将会导致大量page fault。在非host OS中处理这些请求时非常耗时的。
- 系统调用重定向。在user mode中完成一系列系统调用需要guest OS而不是user mode进行处理。需要在qemu添加重定向过程。
- 优化和文件系统相关的系统调用。这一部分应该是作者尝试出来的。因为每个固件中都有对应的文件系统,而一般情况下对文件系统读写需要走系统调用,这样开销会比较大。作者通过将这种读取写入直接写入到host OS目录下的固件文件系统中,从而绕开了guest OS读写的开销
为了达到这一目的,作者在系统的几个方面做了修改
- 启动时,使用system mode,这里借助firmadyne的模拟工作以及DECAF来判断何时进入到可以fork的阶段
- fork时,不是选择AFL默认的entry point,而是选择接收到网络信息的时刻。此时也需要复制一份DECAF的VMI,但是这样复制一份的开销也比较大。作者提出了一种轻量级的复制VMI的策略,因为在host OS中处理缺页中断是比较快的,因此可以在复制这里的VMI中使用COW,从而只需要保存一份核心的VMP snapshot即可,其余部分用COW来修改。
- 创建输入。由于AFL一般输入是命令行,需要将其改为接受网络消息的时刻,可以通过在user-mode的模拟中进行插桩,从而不用将其重定向到system mode,而是直接接受来自AFL的输入并继续处理,测试其用户层面的代码
- 收集反馈信息。可以直接通过QEMU翻译过程中对分支语句进行插装,获取反馈率。这一部分和AFL在qemu user mode中的插装是类似的。
实验
回到刚才作者的实验目的,接下来测试两点
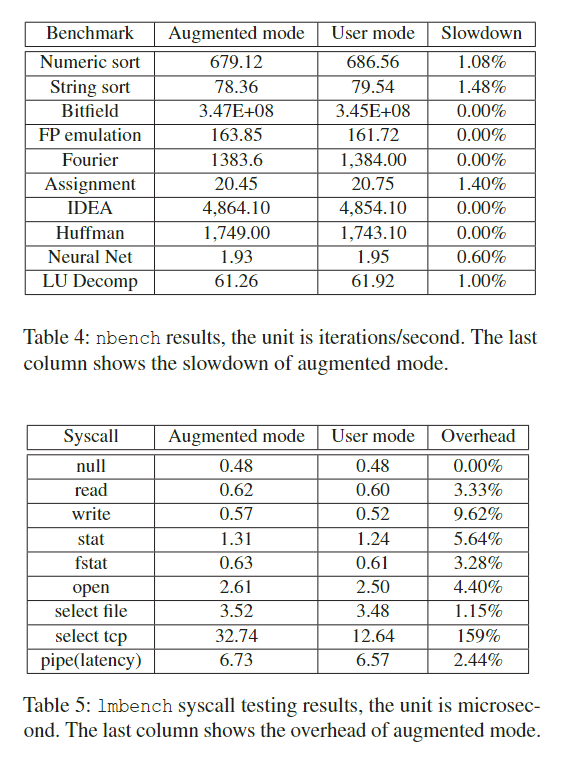
- 在augmented mode和纯user mode下模拟的在效率差距为多少(对应table4)
- user mode下的syscall redirection 会为模拟增加多少开销(对应table5)
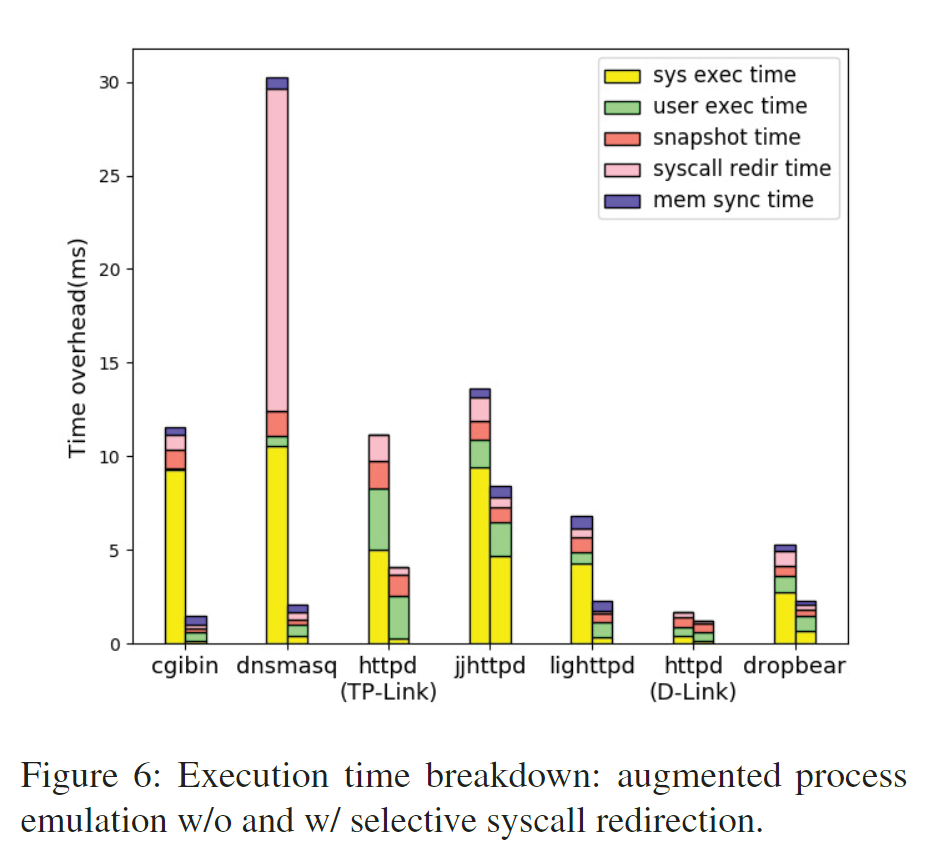
此外,作者还调研了在每次fuzzing过程中各个部分的耗时情况,如下所示。可以看到augmentated emulation提升最大的地方在于将code translation基本减少到0,这是由于使用user mode可以将指令翻译不局限在同一个物理页面上。此外,还有user execution time的大量减少,这主要是因为减少了大量的地址翻译时间(避免system mode中的地址翻译)
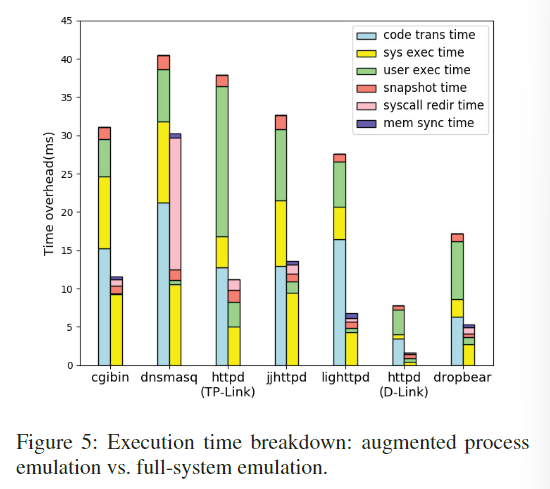
作者还调研了syscall redirection的作用。可以看到大量的sys exec time明显下降了,这是因为host OS帮助guest OS执行了大量代码,例如文件系统读写等。
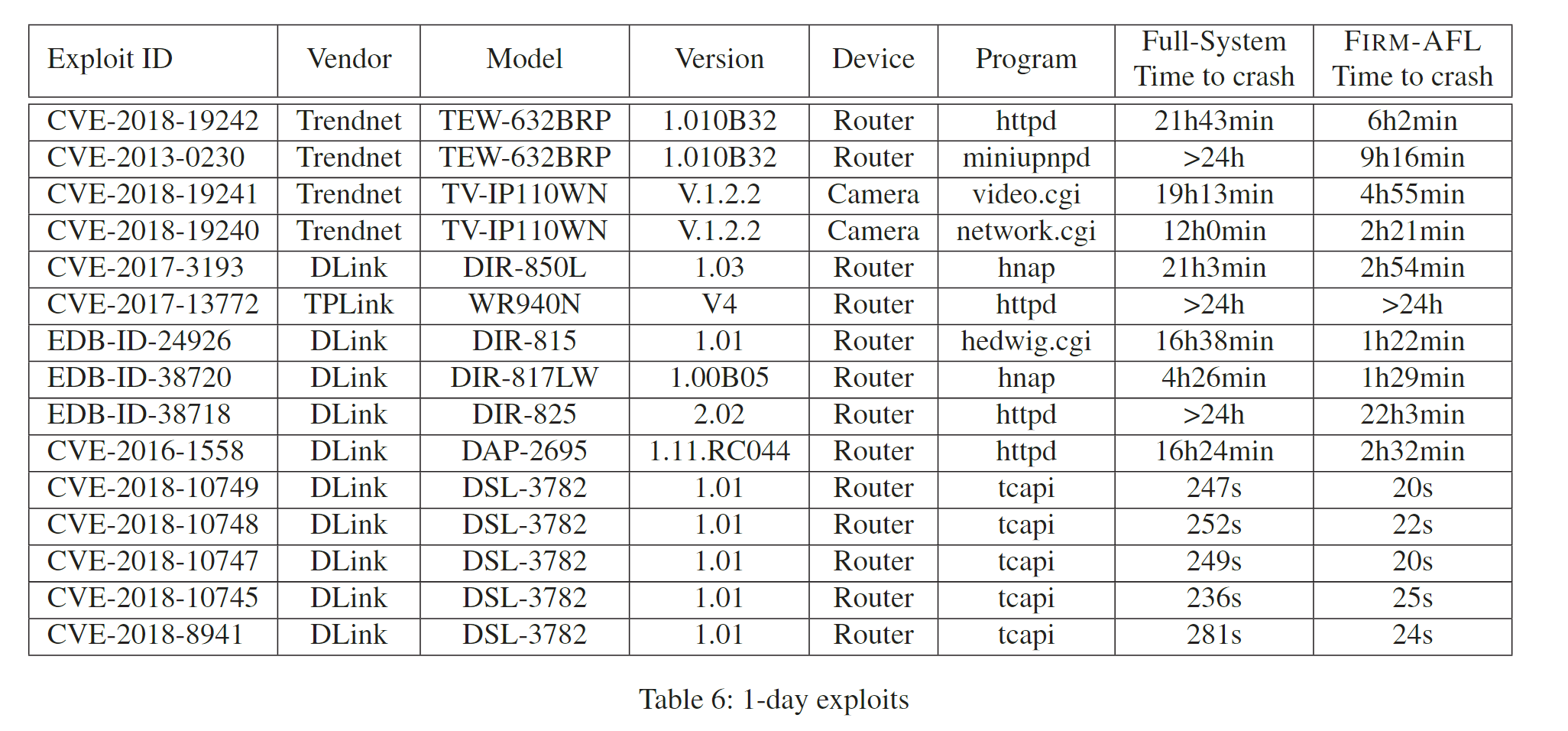
最后,作者比较了fuzzing过程中full system emulation和augmented emulation的速度,可以发现大部分都提升了4~10倍。